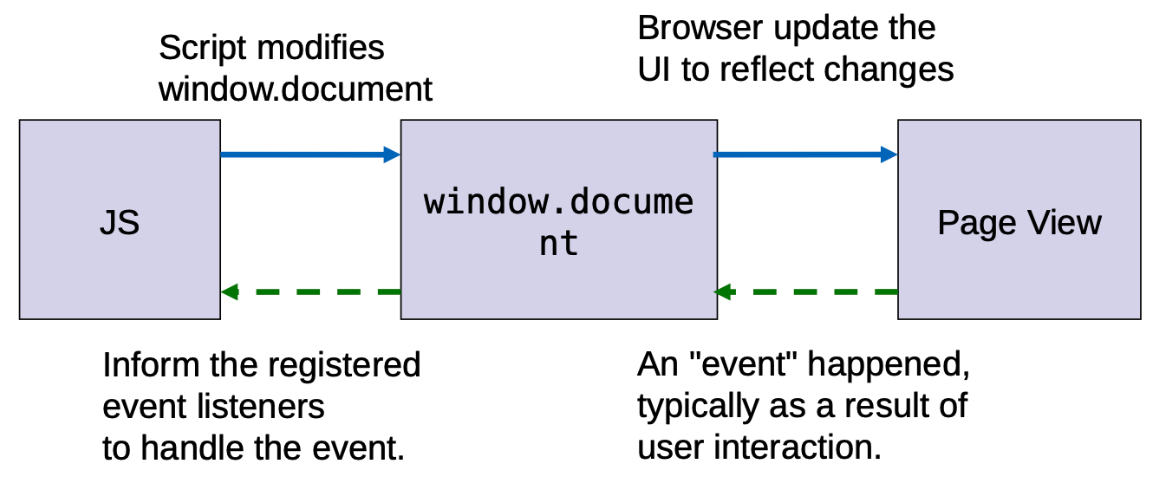
let nodes = document.querySelectorAll('.foo') for (let i = 0; i < nodes.length; i++) console.log(nodes[i].text) // OR for (let node of nodes) console.log(node.text)
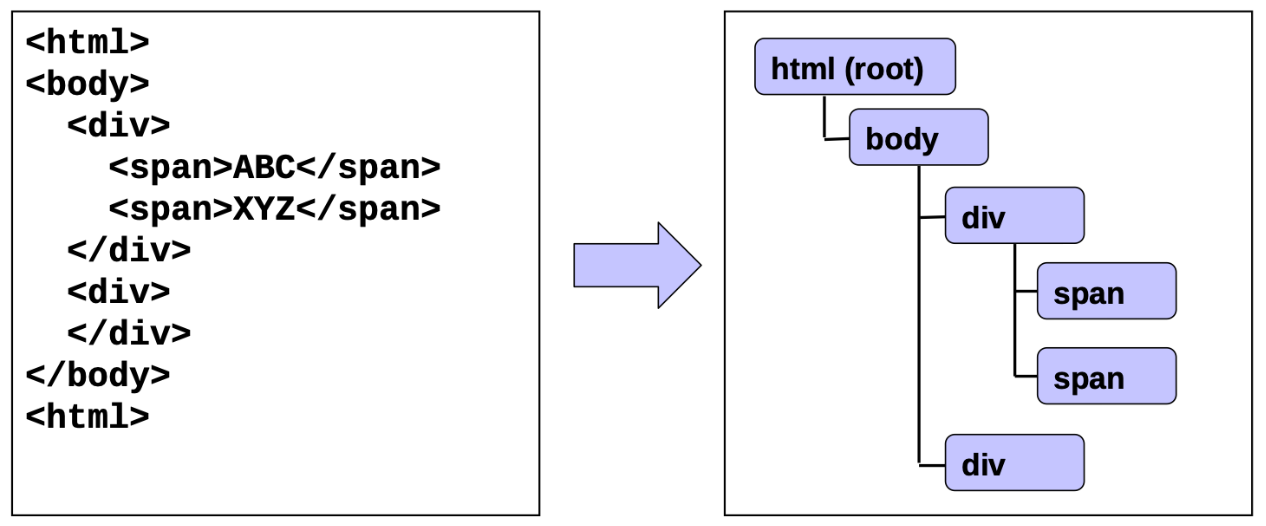
从子树中检索元素
假设我们要检索所有 “div” 元素和 #container 中包含的第一个 “a” 元素
1 2 3 4 5 6 7 8 9 10
// 方法1:搜索整个树两次 let allDivs = document.querySelectorAll('#container div') let firstAnchor = document.querySelector('#container a')
// 方法2:避免搜索整个树两次 // 首先定位 #container let node = document.querySelector('#container') // 在 #container 下搜索子树 let allDivs = node.querySelectorAll('div') let firstAnchor = node.querySelector('a')
Other
本文未包括的内容
遍历文档树
检索注释
在文档对象中其他检索元素的方法
getElementById()
getElementsByTagName()
操作元素
例如 HTML content, text content, attributes, value, CSS style
HTML content
1 2 3
<divid="foo"> ... </div>
1 2 3 4
// Get let htmlStr = document.querySelector('#foo').innerHTML // Set document.querySelector('#foo').innerHTML = htmlStr
分配给.innerHTML的值会被解析,如果该值包含 HTML 标记,则创建相应的树节点
Text content
1 2 3 4
<divid="foo"> <b>ABC</b> <i>XYZ</i> </div>
1 2 3 4 5 6 7 8
// Get let textStr = document.querySelector('#foo').textContent // textStr is "ABC XYZ" // 仅返回 HTML 内容的文本部分,即没有标签内容