CMSC 5724 Data Mining and Knowledge Discovery - Lecture 09
- Centroid-based clustering
Centroid-based clustering
定义
P 为在 Rd 中的点集
给定 o1,o2 ∈ Rd,dist(o1, o2) 相当于 o1 与 o2 之间的距离
假设我们想要划分 k 个 clusters
方法是找到 objects c1, …, ck ∈ Rd(可能不在点集 P 中)
P 被分为 P1, P2, …, Pk
定义 C = {c1, c2, …, ck}
对于每个 o ∈ P,定义 
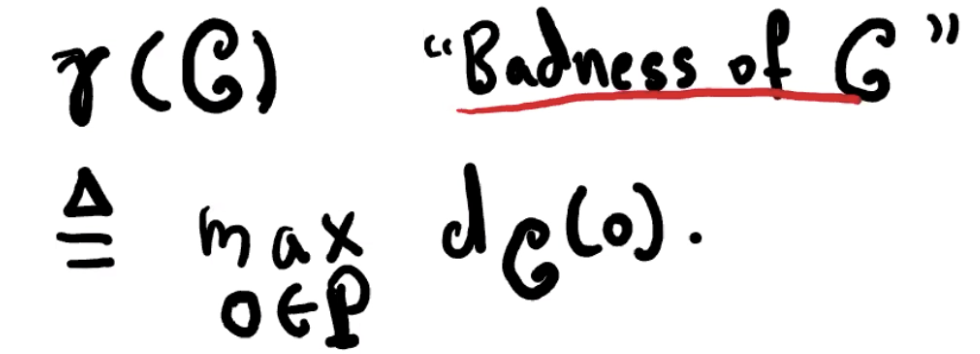
k-center
k-center 问题:求最小的 r(C),在每个 centroid 都在 P 内。
这是一个 NP-hard 问题,即,没有算法可以同时解决 n 与 k 的多项式问题。因此,我们将力求找到具有精确保证的近似答案。
令 C* 为一个 k-center 问题最优的 centroid 集。如果 r(C) < ρ · r(C*),k 个 objects 的 C set 是 ρ-approximate。我们会给出一个算法保证可以返回 2-approximate 解决方案。
2-approximate algorithm

Theorem
k-center 算法是 2-approxiamte
Proof
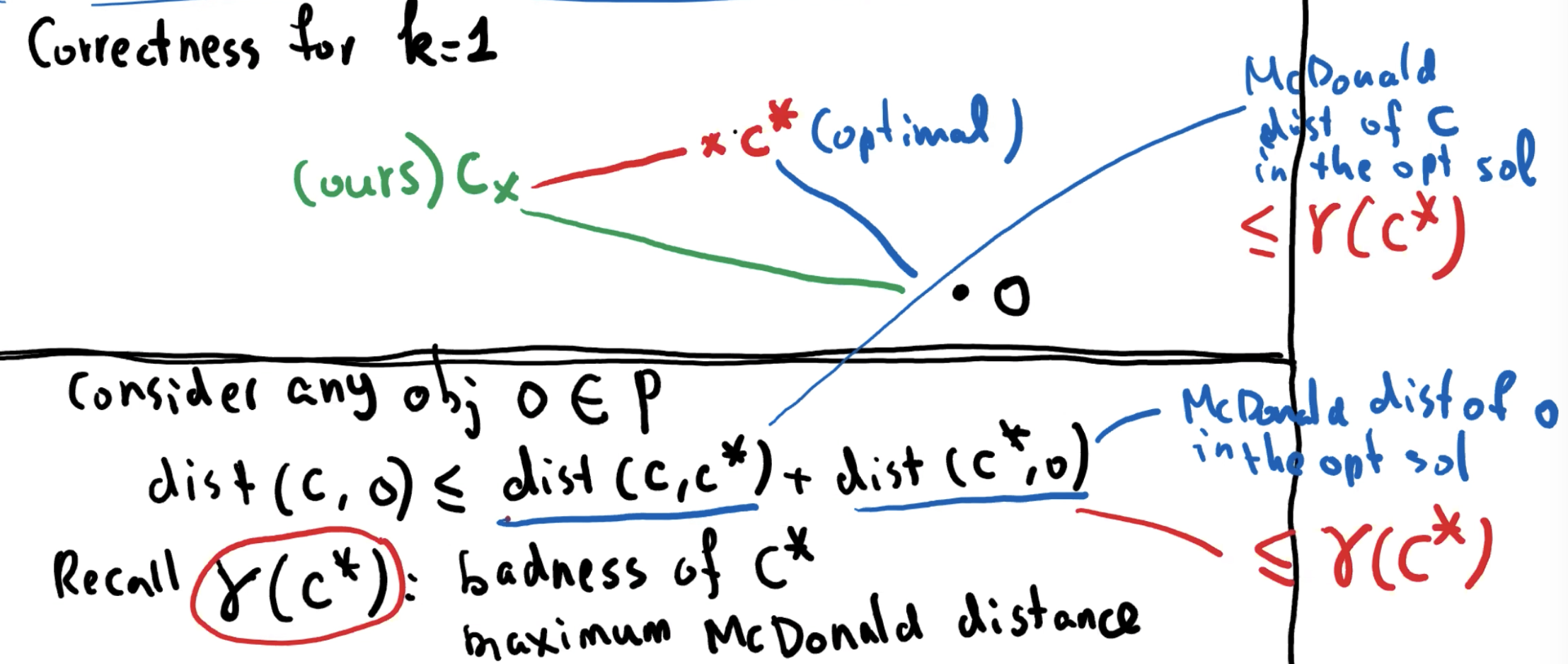
令 C* = {c1*, c2*, …, ck*} 为一个最优 centroid 集,即,它有最小的半径 r(C*)。
令 P1*, P2*, …, Pk* 为最优的 clusters,即, Pi* (1 ≤ i ≤ k)包括所有 objects 可以在所有 C* 中的 centroids,找到 ci* 作为最近的 centroid。
令 C = {c1, c2, …, ck} 为我们算法的输出。我们想要证明 r(C) ≤ 2r(C*)。
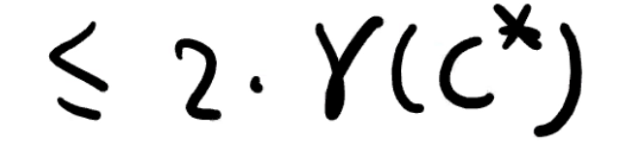

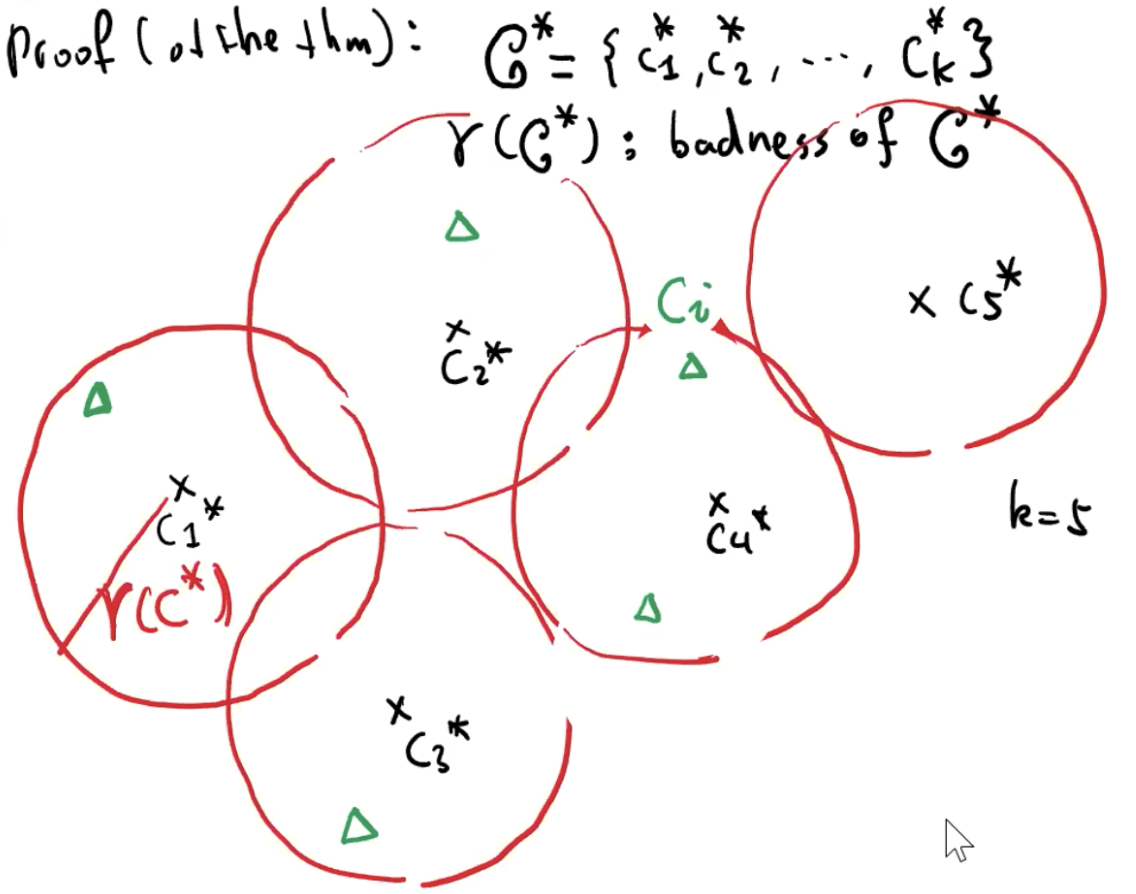
至少有一个圆没有包括在 C 中的任意 centroid,意味着存在一个圆包括 2 个 centroid。因此,
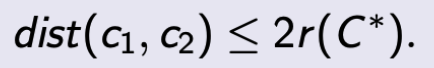
下面我们会证明 r(C) ≤ dist(c1, c2),加上上面证明的 dist(c, 0) ≤ 2r(C*),我们可以完成证明。
在不失一般性前提下,假设我们的算法在 c1 之后选择了 c2。因此,c2 此时具有最大的 centroid 距离。因此,此时任何对象 o ∈ P 的 centroid 距离最大为 dist(c1, c2)。它的 centroid 距离只能在算法的其余部分减小。因此得出 r(C) ≤ dist(c1, c2)。
k-means
令 P 为 n 个点的点集,并且 k 为一个最多为 n 的整数。令 C 为在 Rd 中的点集,我们将 C 设为 centroid 集。定义对于每个 object o ∈ P,它的 centroid distance 为

dist(o, c) 是 p 与 c 之间的直线距离。C 的 cost 定义为
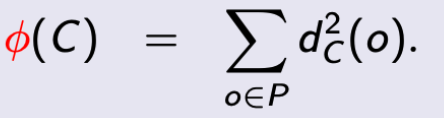
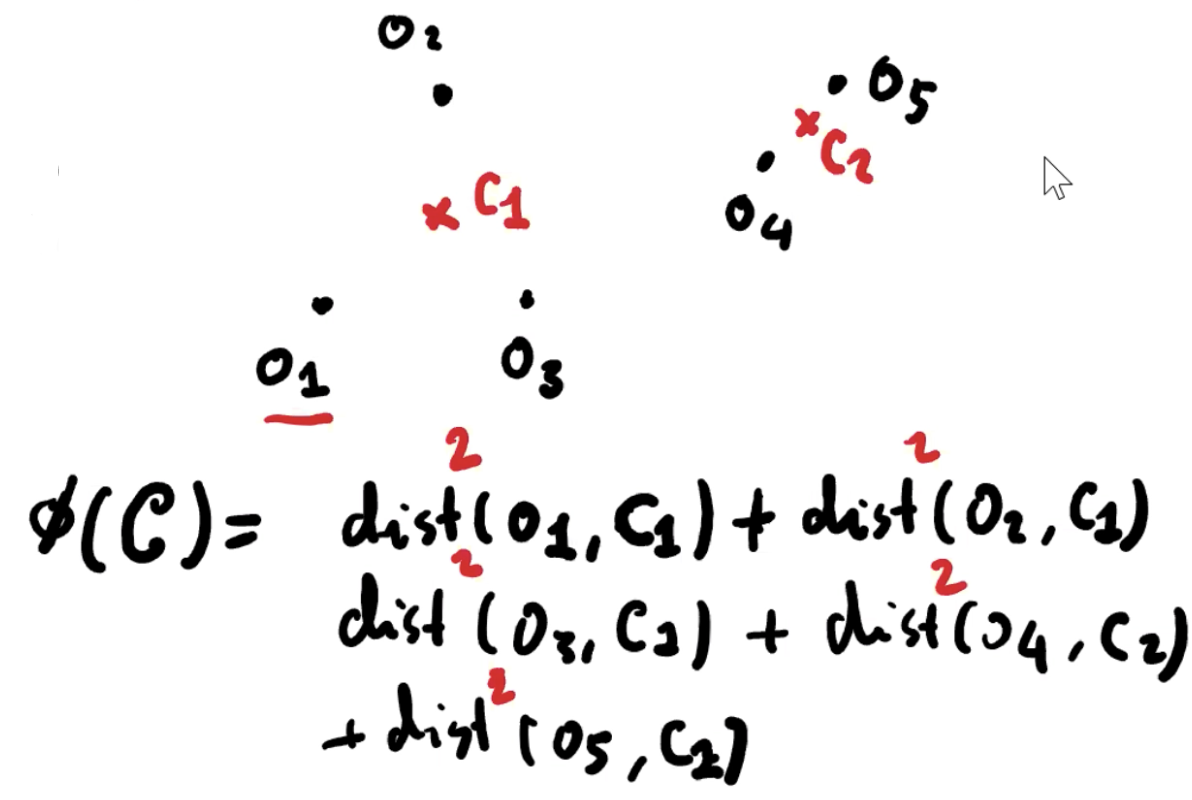
k-means 问题的目标是找到一个 size 为 k 的 centroid 集 C,它有最小的 cost。该问题同样是一个 NP-hard 问题。
点集 P 的 geometric center 是其第 i 个坐标是 P 中 这些点的所有第 i 个坐标的平均值的点。
考虑 k = 1。
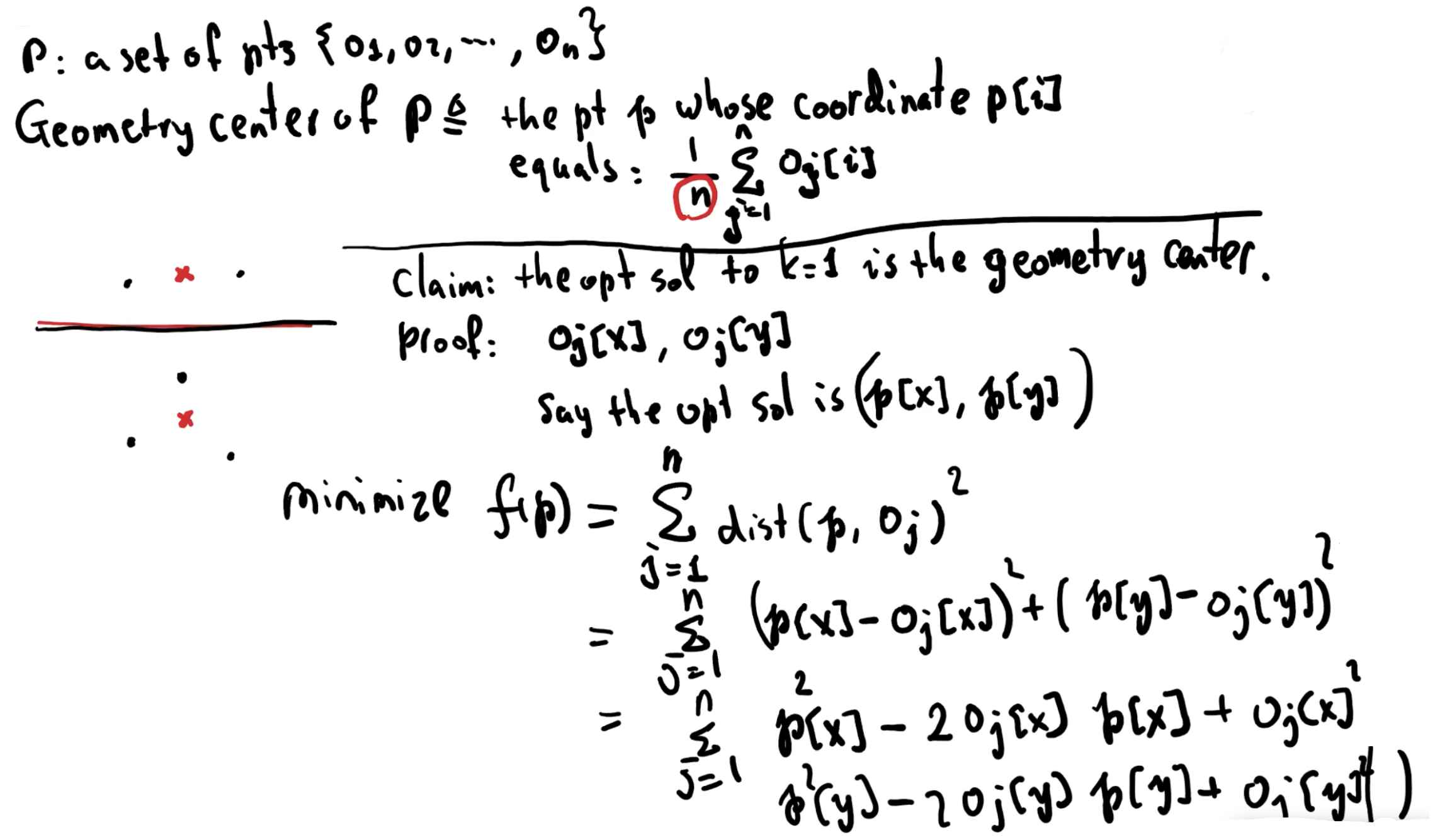
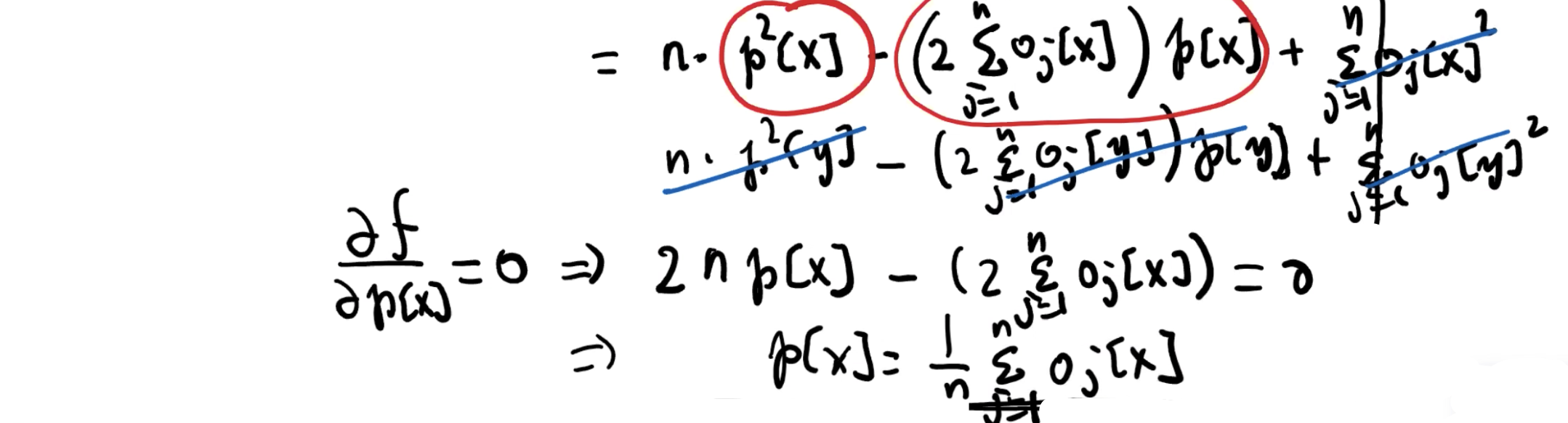
k-means algorithm

Theorm
k-means 算法总是会停下的。