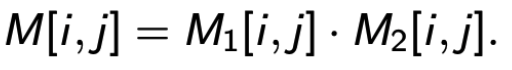CMSC 5724 Data Mining and Knowledge Discovery - Lecture 08
- Classification (Re-defined)
- Linear Classification - Generalized
- Multiclass Perceptron
- Theorem
Classification (Re-defined)
令 A1, …, Ad 为 d 个属性
定义 instance space 为 X = dom(A1) x dom(A2) x … x dom(Ad),dom(Ai) 表示 Ai 可能的值。
定义 label space 为 Y = {1,2, …, k},在 Y 中的元素叫做 class label
每一个 instance-label 对(也叫 object)是一个在 X x Y 中的 (x, y) 对。
x 是一个向量,我们用 x[Ai] 来表示在 Ai 中的向量值。
定义 D 为 X x Y 的概率分布。
目标:给定一个从 D 中提取出来的 object (x, y),我们想从它的属性值 x[A1], …, x[Ad] 预测它的 label y



跟之前学的 classification 的主要的不同就在于 classes 的数量 k 可以为任意值,之前的为 k = 2。我们将之称为 multiclass classification。
Linear Classification - Generalized
一个 generalized linear classifiers 定义为 k 个 d 维向量,w1, w2, …, wk。给定一个在 Rd 中的点 p,classifier 预测它的 label 为
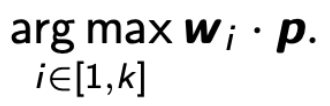
即,它返回 label i ∈ [1, k] 中能提供最大 wi · p 的值
在特殊情况下,i, j ∈ [1, d] 都达到最大值(即 wi · p = wj · p),我们可以使用一些给定的规则,例如预测结果为 i 与 j 中较小的那个。
一个训练集 S 是线性可分的的条件是如果存在 w1, …, wd 满足以下条件
正确分类所有在 S 中的点
对于所有 label 为 l 的点 p ∈ S,对于所有 z ≠ l,
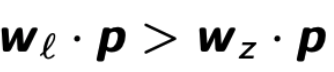 (not quite understand)
(not quite understand)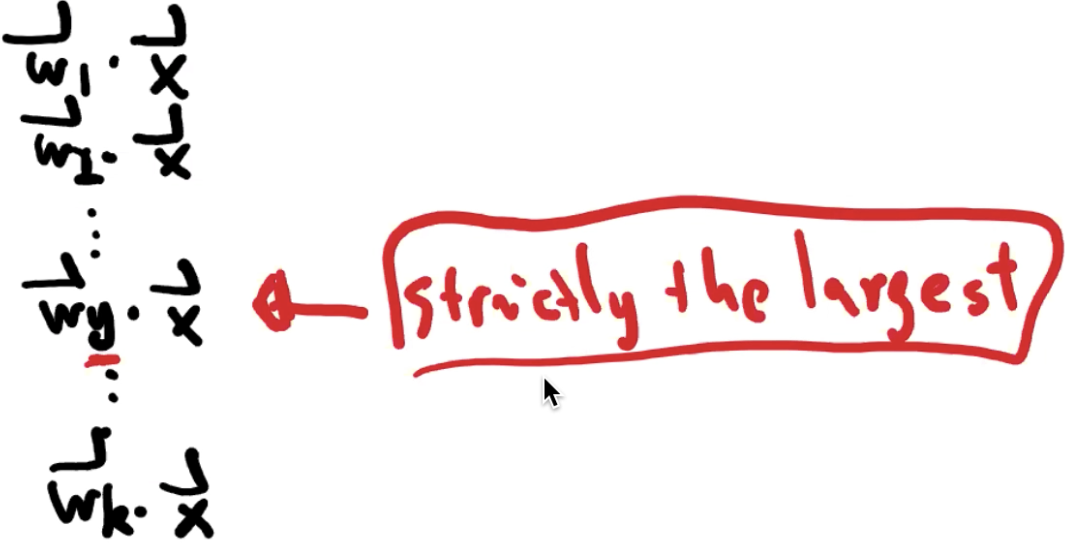
集合{w1, …, wd} 定义为分离 S 的集合。这里的 w 实际写为
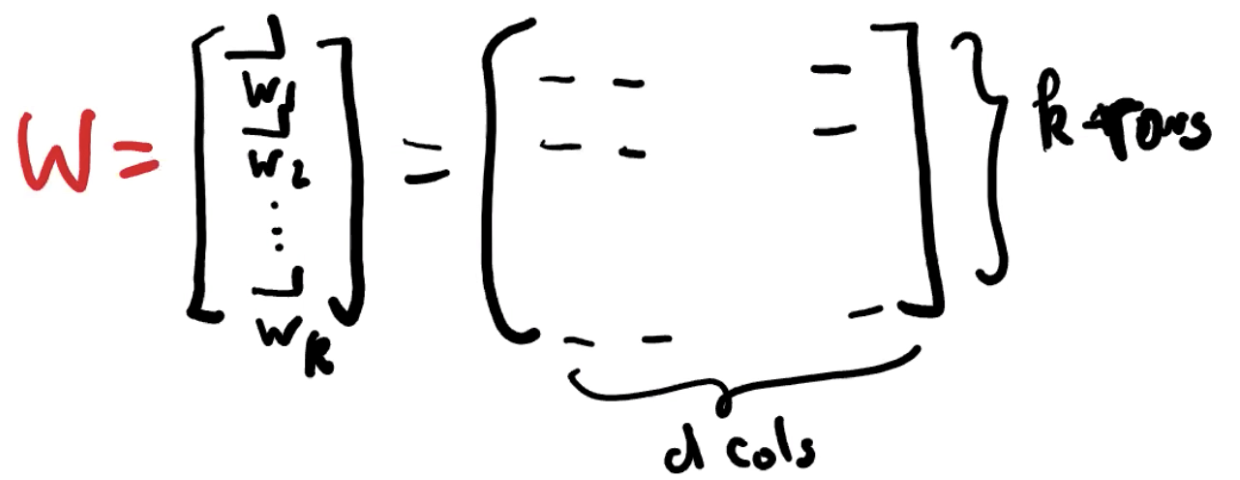
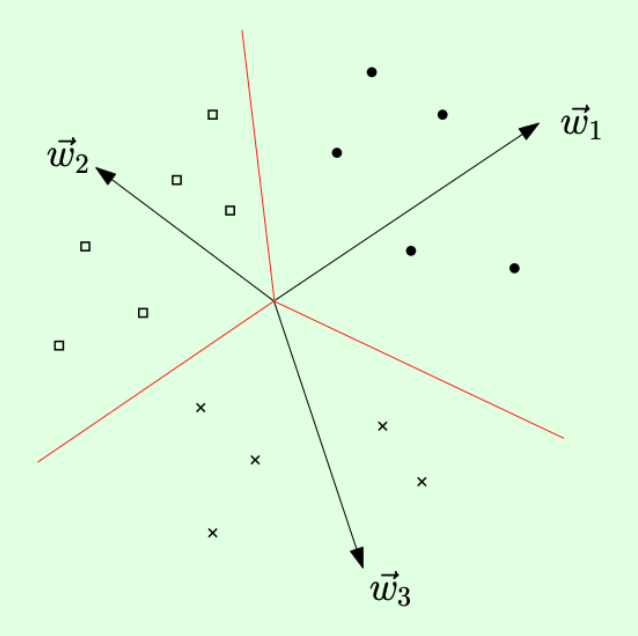
例中,· 的 label 为 1,□ 的 label 为 2,x 的 label 为 3
接下来,我们将讨论一种算法,该算法可扩展 Perceptron 算法以找到一组权重向量来分离 S,前提是 S 是线性可分离的。我们将该算法称为 multiclass Perceptron
Multiclass Perceptron

令 W 为可以分离 S 的权重集 {w1, …, wk}
给定 label 为 l 的点 p ∈ S,我们定义它在 W 下的 margin 为
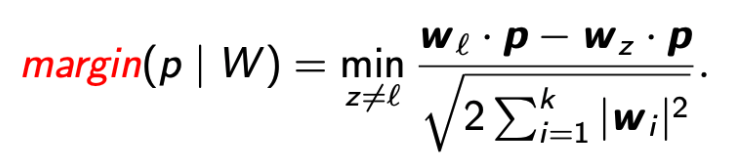
该 margin 是一种衡量 W 如何”确信地”给 p 分类 label 的方法。
W 的 margin 等于 W 下所有点的最小 margin

Theorem
令 W* 为权重集
- 可以分离 S
- 有最大的 margin
定义
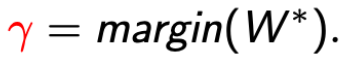
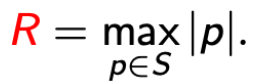
multiclass perceptron 最多在 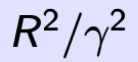 次 violation 点后停止
次 violation 点后停止
令 M 为 d x k 的矩阵。我们用 M[i, j] 来表示在 i 行 j 列的元素。
M 的 Frobenius norm,定义为 |M|F
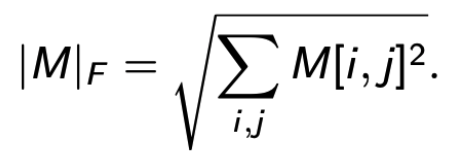
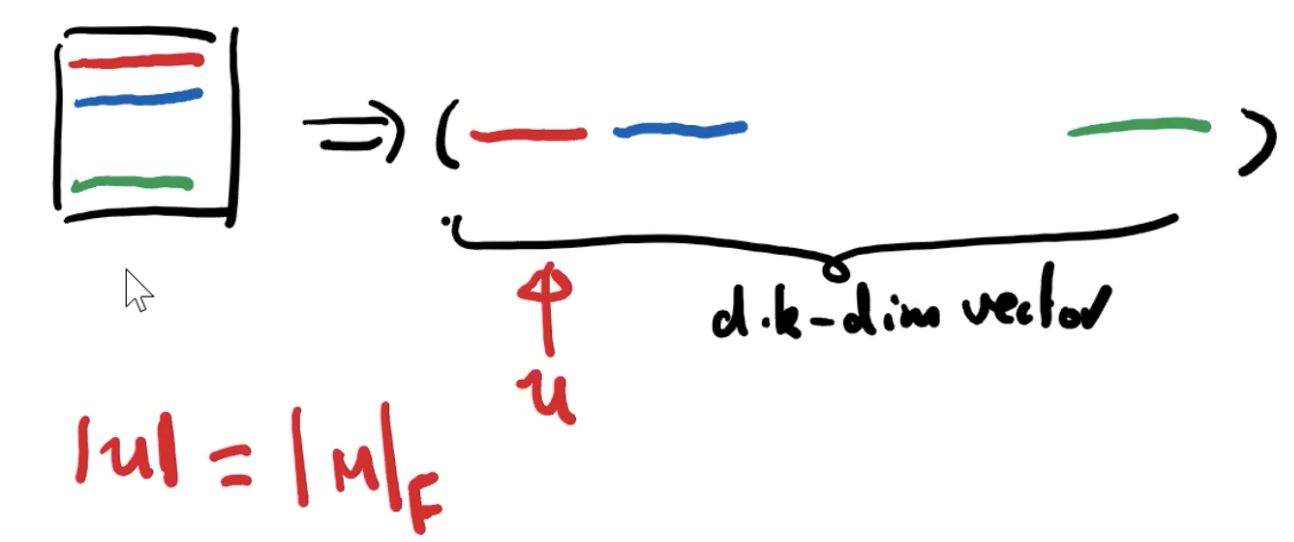
这里是理解上面 norm 的一种简单方法:通过将 M 的所有行连接在一起,将 M 视为(dk)维向量,那么 |M|F,就是该向量的长度。
给定两个 d x k 矩阵 M1,M2,(矩阵)点积运算给出一个新的 d x k 矩阵 M,其中