MySQL基础语法
读《MySQL必知必会》学习MySQL基础语法,记录一下
USE
- 使用crashcourse数据库
1 | USE crashcourse; |
USE语句不返回任何结果。
SHOW
- 显示数据库名
1 | SHOW DATABASES; |
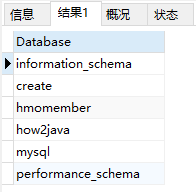
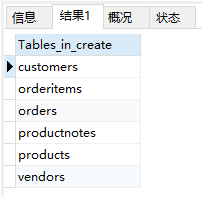
- 显示当前选择的数据库内可用表的列表
1 | SHOW TABLES; |
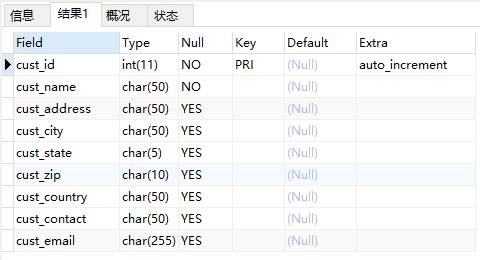
- 给出表名,对每个字段返回一行,行中包含字段名、数据类型、是否允许NULL、键信息、默认值以及其他信息(如字段cust_id的auto_increment)
1 | SHOW COLUMNS FROM customers; |
NOTE:自动增量auto_increment
某些表列需要唯一值。 在每个行添加到表中时, MySQL可以自动地为每个行分配下一个可用编号,不用在添加一行时手动分配唯一值(这样做必须记住最后一次使用的值) 。如果需要它,则必须在用CREATE语句创建表时把它作为表定义的组成部分。
其他SHOW语句:
- SHOW STATUS,用于显示广泛的服务器状态信息;
- SHOW CREATE DATABASE和SHOW CREATE TABLE,分别用来显示创建特定数据库或表的MySQL语句;
- SHOW GRANTS,用来显示授予用户(所有用户或特定用户)的安全权限;
- SHOW ERRORS和SHOW WARNINGS, 用来显示服务器错误或警告消息。
SELECT
- 用SELECT语句从products表中检索一个名为prod_name的列 (如果没有明确排序查询结果 ,则返回的数据的顺序没有特殊意义 )
1 | SELECT prod_name |
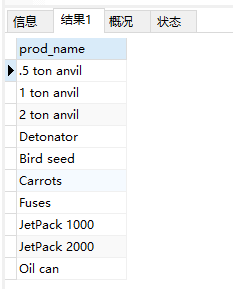
- 从products表中选择3列
1 | SELECT prod_id, prod_name, prod_price |
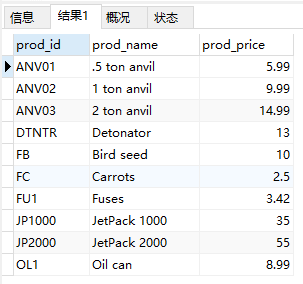
- 检索所有列
1 | SELECT * |
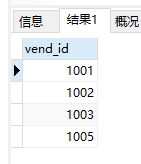
- 检索不同的行,只返回不同的vend_id行
1 | SELECT DISTINCT vend_id |
LIMIT
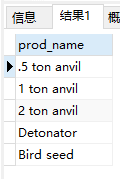
- 限制结果。使用LIMIT 5返回不多于5行
1 | SELECT prod_name |
NOTE:LIMIT
- 为得出下一个5行,可以指定开始行和行数,如
LIMIT 5,5,表示从行5开始的5行。第一个数为开始位置,第二个数为要检索的行数。 - 行0:检索出来的第一行为行0而不是行1。因此, LIMIT 1, 1将检索出第二行而不是第一行。
- 在行数不够时 ,MySQL将只返回它能返回的那么多行
- 使用完全限定的表名
1 | SELECT products.prod_name |
ORDER BY
- 使用
ORDER BY子句取一个或多个列的名字,据此对输出进行排序
1 | SELECT prod_name |
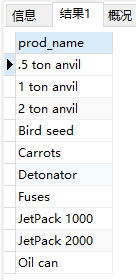
- 按多个列排序。检索3个列,并按其中两个列对结果进行排序,首先按价格,然后再按名称排序
1 | SELECT prod_id, prod_price, prod_name |
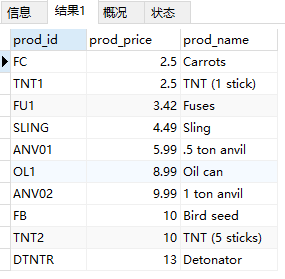
- 按降序排序。
1 | SELECT prod_id, prod_price, prod_name |
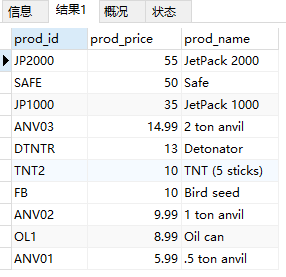
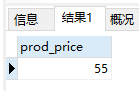
- 使用
ORDER BY和LIMIT组合,prod_price DESC保证行由最贵到最便宜检索,LIMIT 1告诉MySQL仅返回一行
1 | SELECT prod_price |
NOTE:ORDER BY子句的位置
在给出ORDER BY子句时,应该保证它位于FROM子句之后。如果使用LIMIT,它必须位于ORDER BY之后。
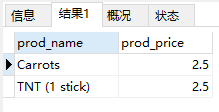
WHERE
- 在
SELECT语句中,数据根据WHERE子句指定的搜索条件进行过滤。
1 | SELECT prod_name, prod_price |
NOTE:
SQL过滤与应用过滤。数据也可以在应用层过滤。为此目的, SQL的SELECT语句为客户机应用检索出超过实际所需的数据,然后客户机代码对返回数据进行循环,以提取出需要的行。通常,这种实现并不令人满意。因此,对数据库进行了优化,以便快速有效地对数据进行过滤。让客户机应用(或开发语言)处理数据库的工作将会极大地影响应用的性能,并且使所创建的应用完全不具备可伸缩性。此外,如果在客户机上过滤数据,服务器不得不通过网络发送多余的数据,这将导致网络带宽的浪费。
WHERE子句的位置。在同时使用ORDER BY和WHERE子句时,应该让ORDER BY位于WHERE之后WHERE子句操作符
1 | #检查单个值 |
AND OR
- AND`操作符,必须满足所有条件
1 | SELECT prod_id, prod_price, prod_name |
OR操作符,匹配任一条件即可
1 | SELECT prod_name, prod_price |
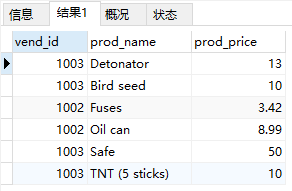
AND和OR组合使用。列出价格为10元(含)以上且由1002或1003制造的所有产品
1 | SELECT prod_name, prod_price |
NOTE:
- SQL的计算次序中
AND的优先级比OR更高,因此在不加括号时会优先计算AND两侧条件 - 任何时候使用具有AND和OR操作符的WHERE子句,都应该使用圆括号明确地分组操作符。不要过分依赖默认计算次序。
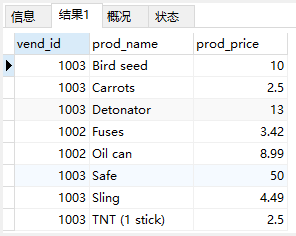
IN
IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配
1 | SELECT vend_id, prod_name, prod_price |
NOTE:IN操作符优点
- 在使用长的合法选项清单时,
IN操作符的语法更清楚且更直观。 - 在使用
IN时,计算的次序更容易管理(因为使用的操作符更少)。 IN操作符一般比OR操作符清单执行更快。IN的最大优点是可以包含其他SELECT语句,使得能够更动态地建立WHERE子句。
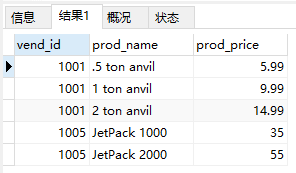
NOT
- WHERE子句中的NOT操作符有且只有一个功能,那就是否定它之后所跟的任何条件。
1 | SELECT vend_id, prod_name, prod_price |
NOTE:MySQL中的NOT
MySQL 支 持 使 用 NOT 对 IN 、 BETWEEN 和EXISTS子句取反,这与多数其他DBMS允许使用NOT对各种条件
取反有很大的差别。
LIKE
NOTE:
- 通配符(wildcard):用来匹配值的一部分的特殊字符
- 搜索模式(search pattern):由字面值、通配符或两者组合构成的搜索条件
- 谓词(predicate): 操作符何时不是操作符?答案是在它作为谓词( predicate)时。从技术上说, LIKE是谓词而不是操作符。虽然最终的结果是相同的,但应该对此术语有所了解
- 百分号(%)通配符。 例:找出所有以词jet起头的产品
1 | SELECT prod_id, prod_name |
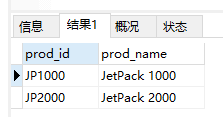
- 匹配任意位置
1 | SELECT prod_id, prod_name |
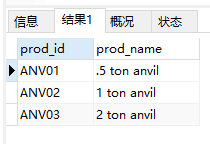
- 找出s起头以e结尾所有产品
1 | SELECT prod_id, prod_name |
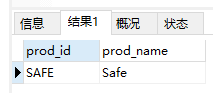
NOTE:
- 注意尾空格:尾空格可能会干扰通配符匹配。例如,在保存词anvil 时 , 如 果 它 后 面 有 一 个 或 多 个 空 格 , 则 子 句 WHEREprod_name LIKE ‘%anvil’将不会匹配它们,因为在最后的l后有多余的字符。解决这个问题的一个简单的办法是在搜索模式最后附加一个%。一个更好的办法是使用函数
- 注意NULL:虽然似乎%通配符可以匹配任何东西,但有一个例外,即NULL。即使是WHERE prod_name LIKE ‘%’也不能匹配用值NULL作为产品名的行
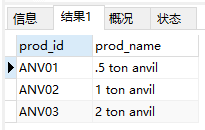
- 下划线(_)通配符。用途与%一样,但下划线只匹配单个字符而不是多个字符。
1 | SELECT prod_id, prod_name |
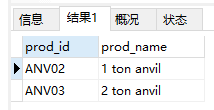
1 | SELECT prod_id, prod_name |
NOTE:
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据
正则表达式
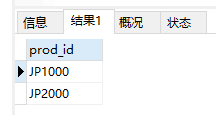
- 基本字符匹配。
1 | SELECT prod_id |
NOTE:匹配不区分大小写。
MySQL中的正则表达式匹配(自版本3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大小写,可使用BINARY关键字,如WHERE prod_name REGEXPBINARY 'JetPack .000'
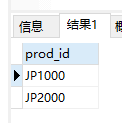
- 进行
OR匹配。也可以给出两个以上的OR条件,如1000|2000|3000
1 | SELECT prod_id |
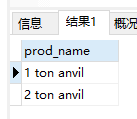
- 匹配几个字符之一。使用正则表达式
[123]定义一组数字,匹配1或2或3
1 | SELECT prod_name |
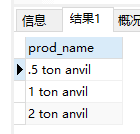
- 范围匹配
1 | SELECT prod_name |
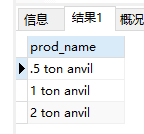
- 匹配特殊字符。如果使用
.,则会匹配任意字符
1 | SELECT prod_name |
NOTE:
- 匹配
\。为了匹配\本身,需要使用\\\ - **
\或\\?**。多数正则表达式实现使用单个反斜杠转义特殊字符,以便能使用这些字符本身。但MySQL要求两个反斜杠( MySQL自己解释一个,正则表达式库解释另一个)。
- 匹配字符类

- 匹配多个实例

1 | SELECT prod_name |
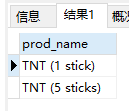
分析:正则表达式\\([0-9] sticks?\\)需要解说一下。 \\(匹配(,[0-9]匹配任意数字(这个例子中为1和5),sticks?匹配stick和sticks( s后的?使s可选,因为?匹配它前面的任何字符的0次或1次出现),\\)匹配)。没有?,匹配stick和sticks会非常困难
1 | SELECT prod_name |
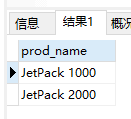
分析:[:digit:]匹配任意数字,因而它为数字的一个集合。 {4}确切地要求它前面的字符(任意数字)出现4次,所以[[:digit:]]{4}匹配连在一起的任意4位数字
- 定位符
1 | SELECT prod_name |
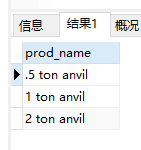
分析:之前的例子都是匹配一个串中任意位置的文本。^[0-9\\.]只在.或任意数字为串中第一个字符时才匹配它们
NOTE:使REGEXP起类似LIKE的作用。LIKE和REGEXP的不同在于, LIKE匹配整个串而REGEXP匹配子串。利用定位符,通过用^开始每个表达式,用$结束每个表达式,可以使REGEXP的作用与LIKE一样。
计算字段
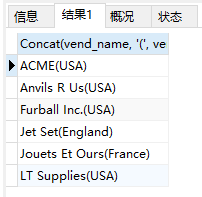
例:vendors表包含供应商名和位置信息。假如要生成一个供应商报表,需要在供应商的名字中按照name(location)这样的格式列出供应商的位置。此报表需要单个值,而表中数据存储在两个列vend_name和vend_country中。此外,需要用括号将vend_country括起来。
1
2
3SELECT Concat(vend_name, '(', vend_country, ')')
FROM vendors
ORDER BY vend_name;
- 使用
RTrim()函数删除数据右侧多余的空格来整理数据。也可以使用LTrim()删除左边的空格,Trim()删除左右两边的空格
1 | SELECT Concat(RTrim(vend_name), '(', RTrim(vend_country), ')') |
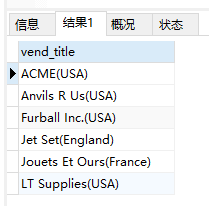
- 使用别名。使用
AS关键字将vend_title作为新计算列的名字
1 | SELECT Concat(RTrim(vend_name), '(', RTrim(vend_country), ')') AS |
NOTE:
- 别名的其他用途。别名还有其他用途。常见的用途包括在实际的表列名包含不符合规定的字符(如空格)时重新命名它,在原来的名字含混或容易误解时扩充它。
- 导出列。别名有时也称为导出列( derived column),不管称为什么,它们所代表的都是相同的东西。
- 执行算术运算
1 | SELECT prod_id, |

函数
NOTE:函数没有SQL的可移植性强。
能运行在多个系统上的代码称为可移植的( portable)。相对来说,多数SQL语句是可移植的,在SQL实现之间有差异时,这些差异通常不那么难处理。而函数的可移植性却不强。几乎每种主要的DBMS的实现都支持其他实现不支持的函数,而且有时差异还很大。
为了代码的可移植,许多SQL程序员不赞成使用特殊实现的功能。虽然这样做很有好处,但不总是利于应用程序的性能。如果不使用这些函数,编写某些应用程序代码会很艰难。必须利用其他方法来实现DBMS非常有效地完成的工作。
如果你决定使用函数,应该保证做好代码注释,以便以后你(或其他人)能确切地知道所编写SQL代码的含义
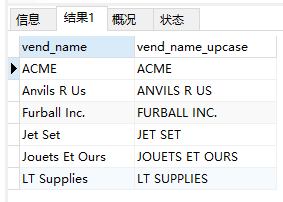
- 本文处理函数
1 | SELECT vend_name, Upper(vend_name) AS vend_name_upcase |
- 常用文本处理函数


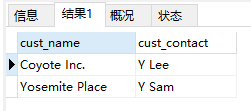
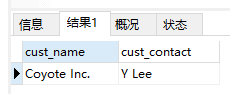
Soundex()通过发音字符和音节检索
1 | SELECT cust_name, cust_contact |
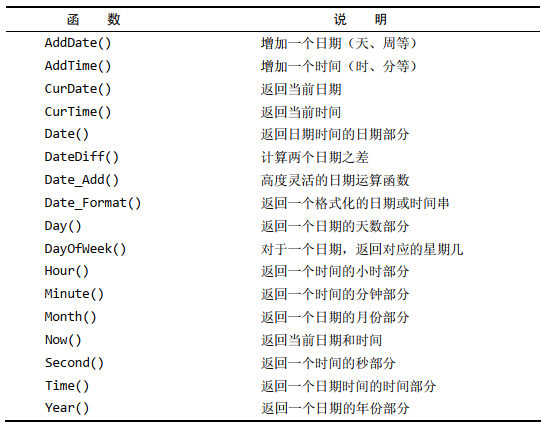
- 常用日期和时间处理函数
- 检索2005年9月1日订单记录
1 | SELECT order_date, cust_id, order_num |
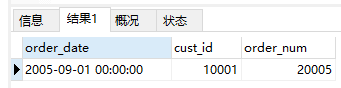
- 检索2005年9月所有订单
1 | SELECT cust_id, order_num |
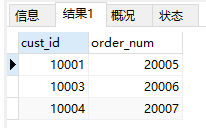
- 数值处理函数
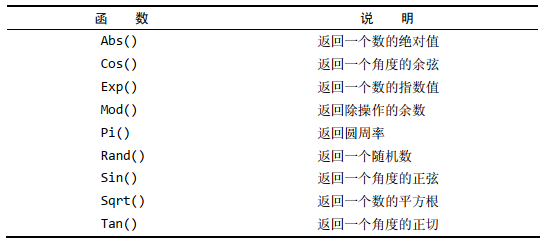
汇总数据

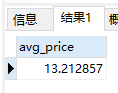
AVG()函数
1 | SELECT AVG(prod_price) AS avg_price |
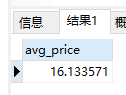
1 | SELECT AVG(prod_price) AS avg_price |
NOTE:
- **只用于单个列
AVG()**。只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。为了获得多个列的平均值,必须使用多个AVG()函数。 - NULL值。
AVG()函数忽略列值为NULL的行
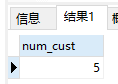
COUNT()函数
1 | #返回customers表中客户的总数 |
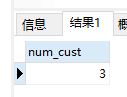
1 | #只对具有电子邮件地址的客户计数 |
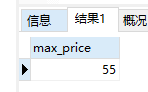
MAX()函数
1 | #返回products表中最贵物品的价格 |
NOTE:
- 对非数值数据使用
MAX()。虽然MAX()一般用来找出最大的数值或日期值,但MySQL允许将它用来返回任意列中的最大值,包括返回文本列中的最大值。在用于文本数据时,如果数据按相应的列排序,则MAX()返回最后一行 - NULL值。
MAX()函数忽略列值为NULL的行。
MIN()函数
1 | SELECT MIN(prod_price) AS min_price |
SUM()函数
1 | #检索订购物品的总数 |
- 聚集不同值,DISTINCT
1 | #平均值只考虑各个不同的价格 |
- 组合聚集函数
1 | SELECT COUNT(*) AS num_items, |
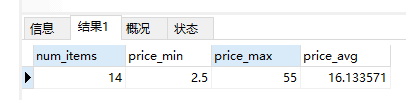
分析:这里用单条SELECT语句执行了4个聚集计算,返回4个值(products表中物品的数目,产品价格的最高、最低以及平均值)
分组数据
GROUP BY创建分组
1 | #对每个vend_id计算num_prods一次 |
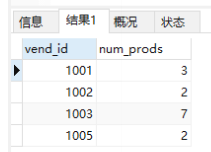
NOTE:
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外, SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后, ORDER BY子句之前。
1 | #使用ROLLUP对每个组及每个分组汇总 |
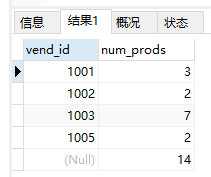
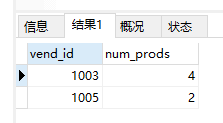
HAVING过滤分组
1 | SELECT vend_id, COUNT(*) AS num_prods |
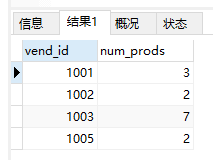
WHERE与HAVING同时使用的情况
1 | #通过WHERE进一步过滤上面的例子 |
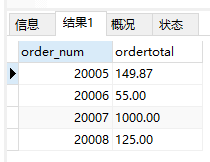
ORDER BY与GROUP BY

1 | SELECT order_num, SUM(quantity*item_price) AS ordertotal |
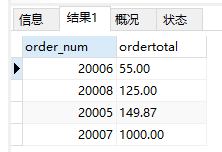
1 | #将总计订单价格排序输出 |
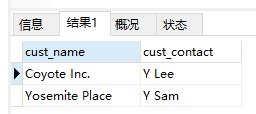
子查询
1 | #检索订购物品TNT2的所有客户 |
NOTE:
- 列必须匹配。在
WHERE子句中使用子查询(如这里所示),应该保证SELECT语句具有与WHERE子句中相同数目的列。通常,子查询将返回单个列并且与单个列匹配,但如果需要也可以使用多个列。 - 子查询和性能。这里给出的代码有效并获得所需的结果。但是,使用子查询并不总是执行这种类型的数据检索的最有效的方法。
联结表
1 | #创建联结 |
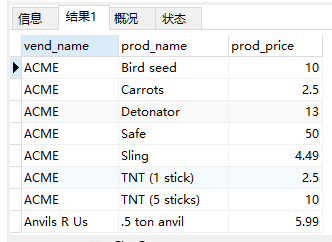
NOTE:
- 完全限定列名。在引用的列可能出现二义性时,必须使用完全限定列名(用一个点分隔的表名和列名)。如果引用一个没有用表名限制的具有二义性的列名, MySQL将返回错误。
- 不要忘了WHERE子句。应该保证所有联结都有WHERE子句,否则MySQL将返回比想要的数据多得多的数据。同理,应该保证WHERE子句的正确性。不正确的过滤条件将导致MySQL返回不正确的数据。
- 叉联结。有时我们会听到返回称为叉联结( cross join)的笛卡儿积的联结类型。
- 内部联结
1 | SELECT vend_name, prod_name, prod_price |
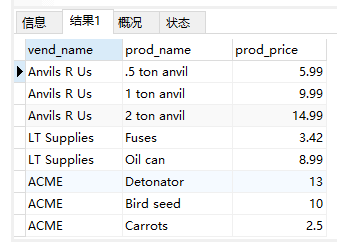
分析:这里,两个表之间的关系是FROM子句的组成部分,以INNER JOIN指定。在使用这种语法时,联结条件用特定的ON子句而不是WHERE子句给出。传递给ON的实际条件与传递给WHERE的相同
- 联结多个表
1 | SELECT prod_name, vend_name, prod_price, quantity |
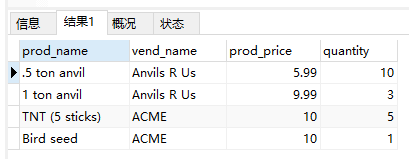
分析:显示编号为20005的订单中的物品。订单物品存储在orderitems表中。每个产品按其产品ID存储,它引用products表中的产品。这些产品通过供应商ID联结到vendors表中相应的供应商,供应商ID存储在每个产品的记录中。这里的FROM子句列出了3个表,而WHERE子句定义了这两个联结条件,而第三个联结条件用来过滤出订单20005中的物品
NOTE:性能考虑
MySQL在运行时关联指定的每个表以处理联结。这种处理可能是非常耗费资源的,因此应该仔细,不要联结
不必要的表。联结的表越多,性能下降越厉害
- 对比子查询
1 | #返回订购产品TNT2的客户列表 |