CMSC 5724 Data Mining and Knowledge Discovery - Lecture 01
- Classification
- Decision Trees
- Generalization Theorem
- Proof
Classification


这里的 U 跟 X 一样,是各个 attribute : A1… Ad 的 Cartesian product(笛卡尔乘积),同时也是 instance space(实例空间);Y 则是 label space(标签空间)。作为 attribute 的 Ai 如下图所示就是 age、education、occupation,他们共同组成了实例空间。而 loan default 就是 label,yes / no 就是 -1 / 1,组成了标签空间。
此时也可以定义 ( instance, label ) - pair(pair有时也叫Object),即 ( x, y ) ∈ X × Y,这里的 x 是向量,即样本空间的一行,如下图所示就是 e.g. age = 28、education = high school、occupation = self-employed。X 跟 Y 的笛卡尔乘积代表了所有的可能性,也就是 D,这在后面会讲到。
其实究其原因,就是我们需要去将这个 D 进行分类,因为 D 的真正分类我们是不知道的,我们就需要通过样本,通过训练集,通过模型,去预测实际的情况。D 也就类似于一个真理,这个真理只有上帝知道,我们能做的就是去通过各种方法找到真理(也有可能只是逼近)。

由于我们只知道向量x,也就是上图中的每一行,为了知道 D,也就是真理,也就是所有的可能性,我们需要 classifier,它通常也叫 hypothesis 或者 concept,定义为 h : X -> Y。它可以理解为一个 function,将 X 中的每一个元素映射到 Y 中,就像是用 Y 的 -1 / 1 给它们打上了标签。这个过程通常是潜藏的(latent),我们看不见的。
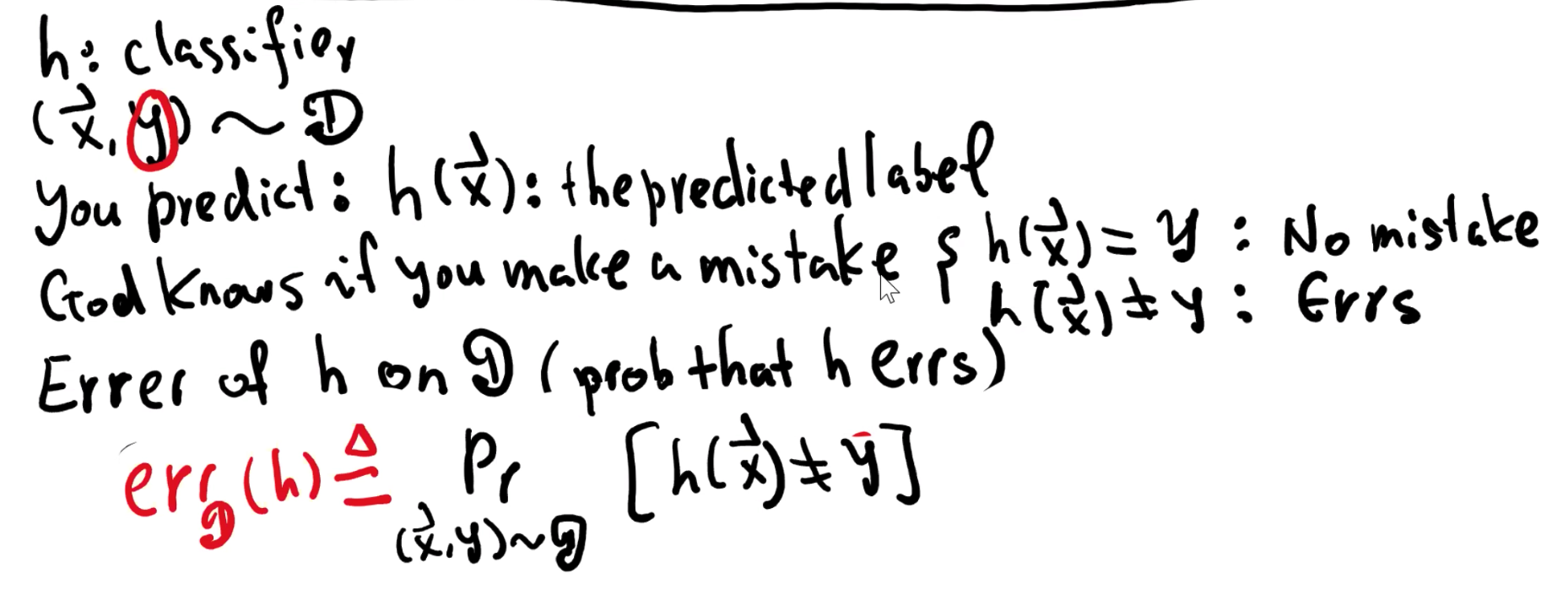
根据上述,我们定义 h : classifier,则我们预测 label 的结果是 h(x)。但这是有可能有错误的,我们将预测的错误结果写作 err_D(h),我们要做的就是尽可能最小化 err_D(h)。

为了更好地预测 D,我们设置了训练集 S。同时我们希望我们生成的 h 的 err_D(h) 尽可能地小。然而这个 err_D(h) 你只能尽可能让它小,你是控制不了的,你能控制的是 err_S(h),即样本误差。

分子为 objects 的数量,这里的 objects 是一个样本对,即一个样本对应一个标签,它属于样本集 S,同时 s.t.(subject to) 代表受后面的约束,该约束条件为预测的结果跟实际结果不一致,即 h(x) ≠ y。
Q & A
Q : “independently” is so important because errS(h) will be close enough to errD(h)?
A : related to large number law 老师表示下节课会谈
Q:why could we minimize err_D(h) just given training set? why not err_S(h)
A : both of them should be considered, but err_S(h) may be secondary.
Q : can we think that D has all the answers we need for (x, y) and that’s why we are trying to get close to it.
A : yes, that’s exactly.
Decision Tree
Hunt’s algorithm
形式上,我们将决策树 T 定义为完整的二叉树,其中
- 每个叶节点都带有一个类标签:yes / no
- 每个内部节点 u :
- 有两个子节点
- 有一个 attribute Au 的 predicate —— Pu(也可以理解为一个判断语句)
当 classification 使用决策树 T 时:给定一个 向量x,我们会对每个节点 u 做如下事情
- 如果 u 是一个叶子节点,返回 u 的 label
- 如果 向量x 满足 Pu,那么去到左子节点,否则,去到右子节点
我们回到上面那个例子

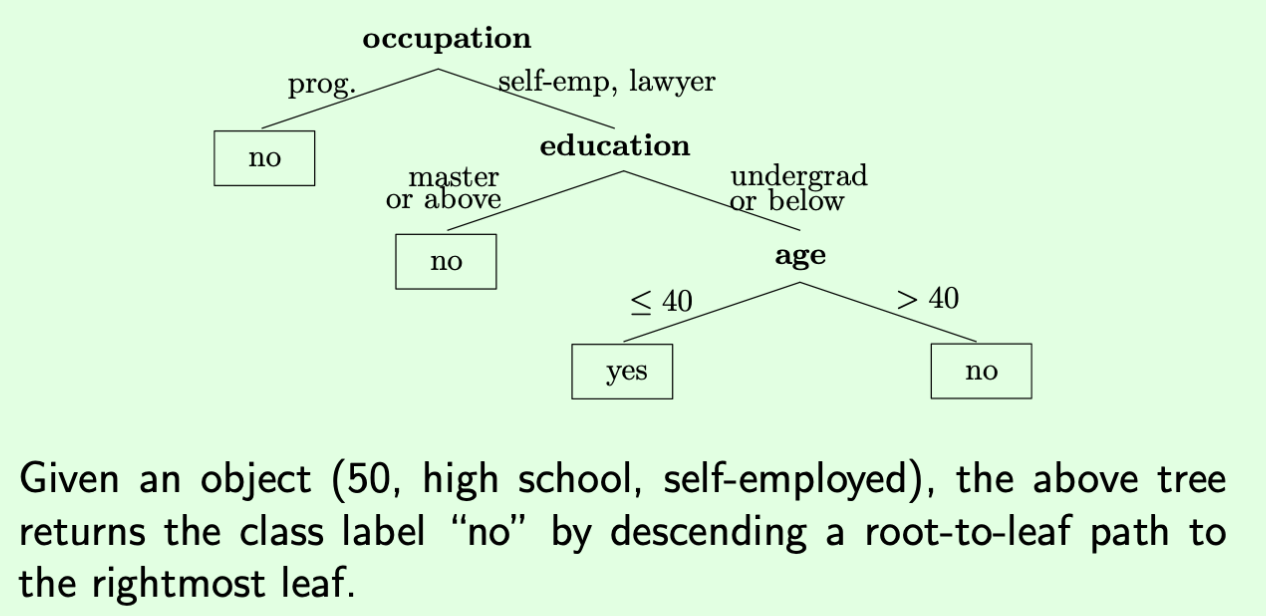
从根节点开始,遇到的每一个判断条件,即 predicate,走向不同的分叉,最后得到 yes / no。
T :决策树
u :T 里的节点
S :训练集
S(u) 定义:
如果 u 是根节点,那么 S(u) 为 S
假设 S(u) 已经被定义,同时假设 u 是一个有着 v1、v2作为孩子节点的内部节点
- S(v1) 定义为满足 S 的对象集
- S(v2) 则为 S(u) \ S(v1),意为在剩下的子集中查找
我们说S(u) split into S(v1) 和 S(v2)
定义 Pu 的方式决定于 Au
- 如果 Au 是 ordinal 有序的(学历也可认为是一种有序):Pu 定义为 Au >= a ∈ dom(Au)
- 如果 Au 是 nominal 名类的(如职业名称):Pu 定义为 Au ∈ R ⊆ dom(Au)(R为dom(Au)的子集)
Quality of a Split
Gini index 基尼系数

其实就是 yes 的百分比与 no 的百分比,当 py = 1,pn = 0 的时候达到 maximum purity,此时 Gini = 0;当 py = 0.5,pn = 0.5时,达到 maximum imputity,此时 Gini = 0.5。Gini 的范围在0到0.5之间。
Principle : the “purer” a set is, the better.
同时,我们定义 split 的基尼系数
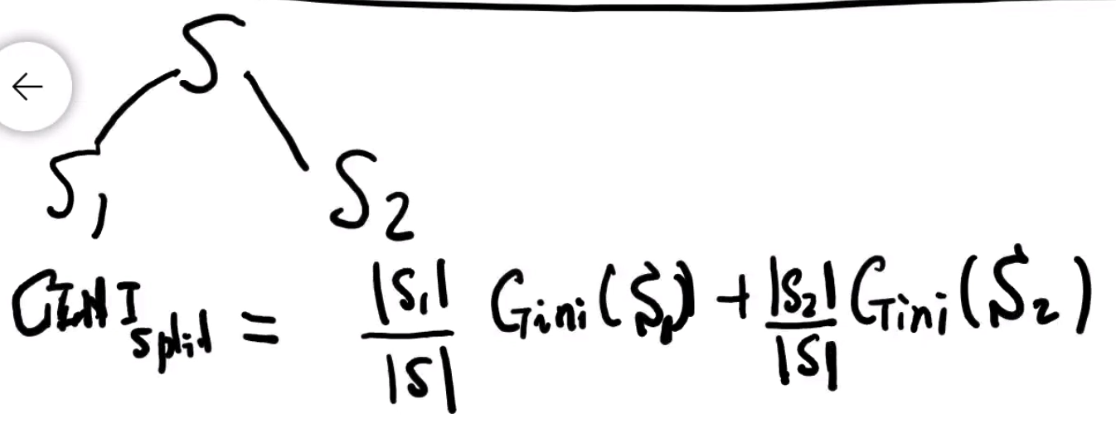
选择方法
令 P 为全世界的一组人,假设没有其他属性 。 我们想学习一个分类器,给定一个随机的人,可以预测他/她是否喝酒。 为此,我们给定训练集 R⊆P。使用 Hunt’s 算法,我们从 R 中获得决策树 T。很容易看出 T 仅具有一个叶子。 令 c 为该叶子的类值(即c =yes / no)。 然后,对于 P 中的每个对象,我们将其类别值预测为c。
c 的哪个值对 P 有用? 这应该与P中有多少人属于“yes”类,以及有多少人属于“no”类有关。 具体来说,让
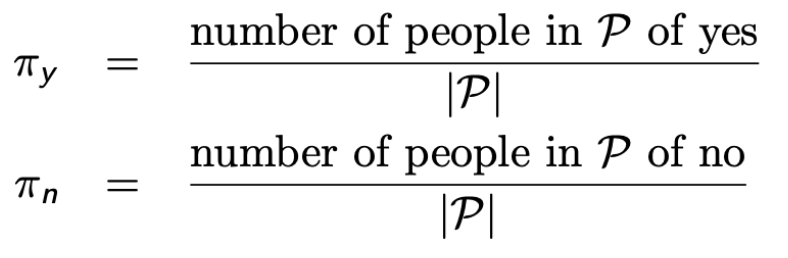
为了使预测 P 中的随机人的错误最小化,如果 πy > πn,则应将 c 设置为 yes,否则将其设置为 no。
举个例子,假设 πy= 0.7 和 πn= 0.3。 然后,如果将 c 设置为yes,我们将有70%的时间是正确的。 另一方面,如果将 c 设置为 no,则只有30%的时间是正确的。
但是,我们不知道 πy 和 πn 的实际值。 因此,我们依靠 R 来猜测这两个值之间的关系。 如果 R 中的 yes 对象多于 no 对象,我们猜 πy>πn,因此将 c 设置为 yes; 否则,我们将 c 设置为 no。 这正是 Hunt’s 算法的作用。
如何确保我们获得良好的猜测? 显然,我们需要 R 的数量大。 这非常直观:如果没有足够的训练数据,则没有办法建立可靠的决策树。 在这种情况下,训练数据没有统计意义。
Generalization Theorem
假设决策树 h 使用 b 个 bits 来表达(因为别人不知道你的决策树是如何编码的,所以必须根据要满足的某些编码约定来表示它,编码方案说明了你的所有约定,以便其他任何人都可以查看该方案并跟你完全相同的方式对任何 h 进行编码,b 取决于你的编码方式,可以看做是上界的长度,可以取任意数字,但是不能是无限数字,因为这样机器无法输出)
我们给定一个概率大小为0到1之间的值 δ,比如是 0.1%(失败),那么它至少以 (1 - δ) = 99.9%(成功)的概率保持以下的不等式:

这里的err_D(h) 即 generalization error 是我需要去约束的,我们使用能够控制的 err_S(h) 来约束。显然,D 的总量是比 S 要大的,因为 D 代表的是实际、是全部,S 只是我们找的训练集,因此要做好训练集不够完整的准备,有可能约束不了 err_D(h),需要加第二项来弥补缺少的信息。

假设 err_S(h) 为0,b 为 2 × 10的6次方,S 为 10的6次方,显然这个训练集 S 太小,会导致后面加的值大于 1,然而 Generalization Theorem 不应该大于1(?)。
如果要使用很大数量的 b 也可以,前提是你的 S 要足够大,如下例

通过选择对的决策树,与足够大的 S,会有很小的 err_S(h),那么你也保证了非常好的 err_D(h),这就是你该如何运用 Generalization Theorem。

就如同图里的分类器也就是绿色线圈住的部分,是正确的”1“,其余是”-1“,可以看出这个分类器很复杂,你能做的就是通过大量的数据集,去尽可能贴近这个分类器,描述它的轮廓,你不可能完美的复现这个分类器,你能做的就是尽可能减少你的划分的红方框与绿色线的距离,也就是误差。
Proof of the Generalization Theorem
Hoeffding Bounds

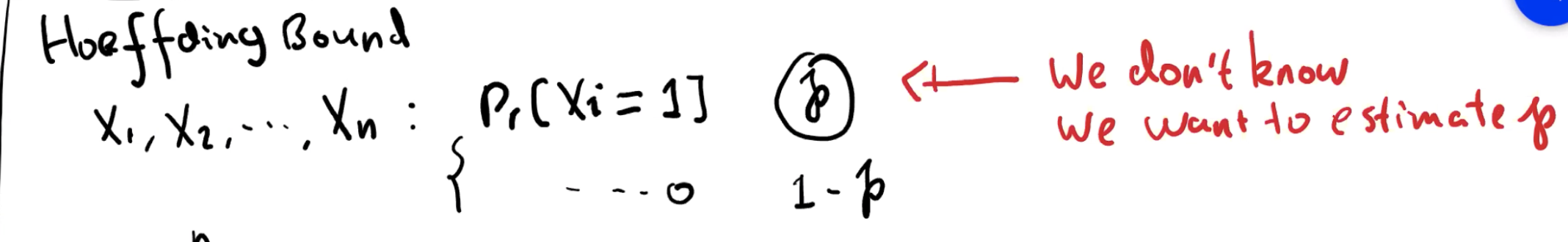
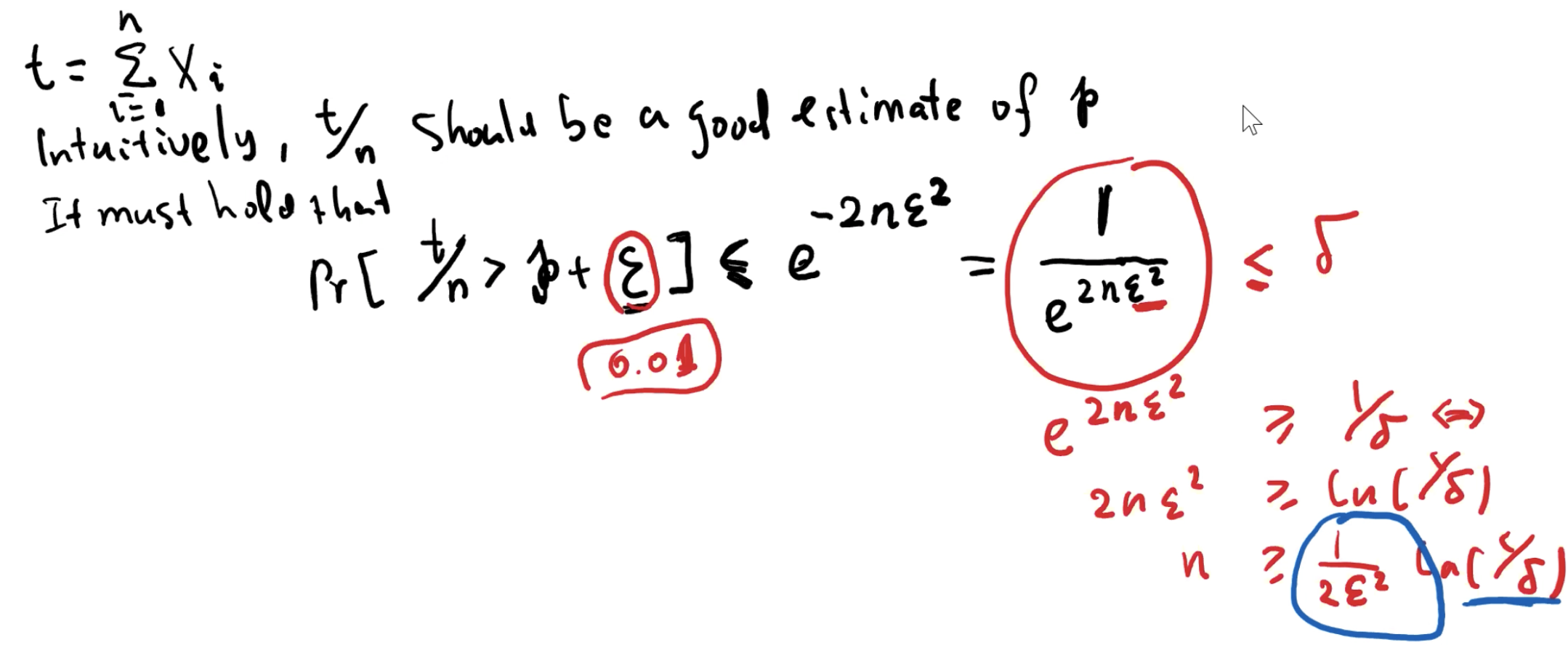
p 是我们想要估计得值,Xi 为独立的随机值,可能是1或0,我们设 t 为 Xi 的和,t 可以表达有多少 X 是1,那么 t/n 就是 p 的估计值。我们令 t/n > p + ε,这里的 ε 就需要是很小的值,因为如果很大的话 t/n 会更大。但是如果 ε 很小的话,n 就会非常大。这意味着如果你想要保证只有 1% 的误差,那么你可能需要 10000 的样本。 Hoeffding Bounds 的用途就是,你需要多少的样本来保证你的准确率,它会给你的训练集一个上限值。
Union Bound


比如 A 的概率是 1%,B 的概率是 2%,那么 A 并 B 的概率会小于等于三,因为可能它们会有交集。
Proof
令 H 作为可以被 b 个 bits 描述的分类器的集合,H ≤ 2的b次方。给定任意一个分类器 h ∈ H,设 S 为 O1, O2, …, On 训练集,并且 n = S。对于每一个 i ∈ [i, n] 的 Oi,定义 Xi = 1为误分类,那么
err_S(h) = 1/n ∑ Xi。
同时,因为每个 S 里的 object 都是独立地取自 D,那么对于每一个 i ∈ [1, n],
Pr[Xi = 1] = err_D(h)。
通过 Hoeffding bounds,我们可以得到
Pr[err_S(h) < err_D(h) - ε] ≤ e^(-2na^2)
此时,我们要让右边尽可能小,

这里的 0.001 就是之前 Generalization Theorem 提到的 δ,至于为什么是这个形式先往下看。因为我们主要控制将这个不等式中的 ε,因此我们将 ε 抽出来,如下图。

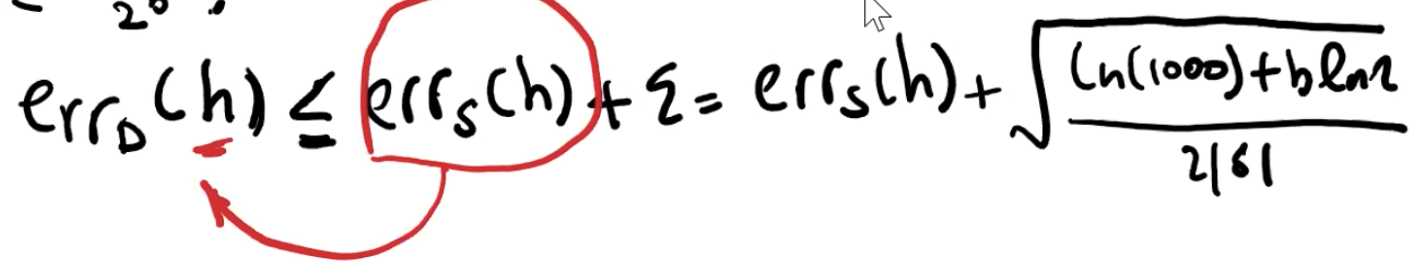
总的来说,就是要通过 err_S(h) 来限定 err_D(h),但是我们是有可能失败的,失败来自于

反过来说,h 发生失败的时候为当

这里是 >,因此我们说它错了。同时我们可以说它发生的概率 ≤ 0.001/2^b。我们可以通过 Union bounds 证明。举个例子,假设老师对每一个同学说你挂科的几率最多为 0.1%/人数总和,那么任意一个学生挂科的概率就为 0.1%,也就是 99.9% 的可能性没有人挂科。回到刚刚的不等式

当不等式左边发生的时候,就是错误发生的时候,我们要让他尽可能小,因此我们就要选择适合的 ε 来达到目的。
Other
Relationship between the error of a classifier h on S and the error of h on D.
将会在后面课程讨论。
另一种问法
Q: Can we somehow prove a connection between err_S(h) and err_D(h)?
A: 由于 err_S(h) 是我们可以控制的,如果能够证明这两者之间的关系,那么就可以知道最大的误差,也就可以知道最优的决策树。那么如何证明呢,见下一讲的 Generalization Theorem。