CMSC 5724 Data Mining and Knowledge Discovery - Lecture 02
- Bayesian Classification
- Naive Bayes Classification
Bayesian Classification

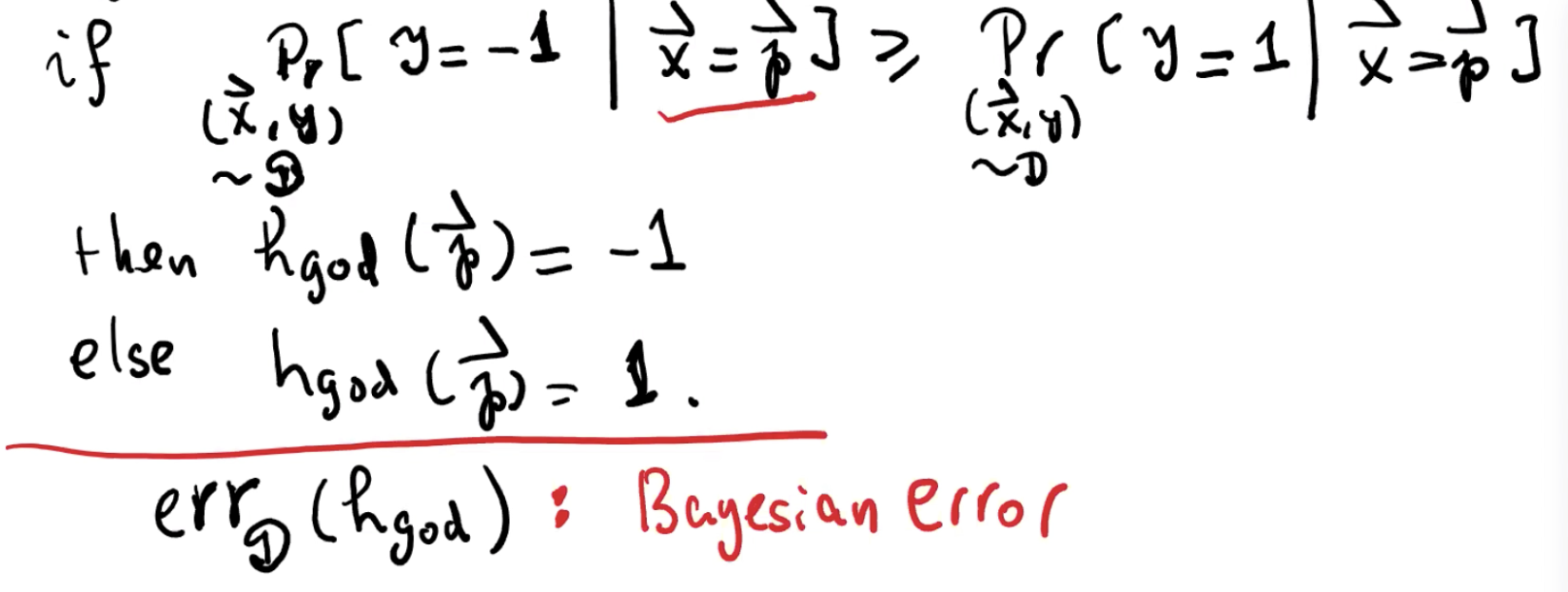
我们给定一个在实例空间的点 p ,即 p ∈ X。如果 Pr[y = -1 | x = p] ≥ Pr[y = 1 | x = p],那么上帝的分类器(最准确的分类器)hgod(p) = -1,反之则 = 1。(这里的Pr[y = -1 | x = p],右上角举例,先限定 x 是年龄为30,学历为 undergraduate,再看标签为 -1 的比例)。但是即便是最准确的分类器,也是有误差的,我们称为 err_D(hgod),也叫贝叶斯误差。
当每个属性都有一个较小的域时,即该属性只有少量可能的值时,贝叶斯分类最有效。 当属性具有较大的域时,我们可以通过离散化来减小其域大小。比如之前的例子,我们可以让年龄划分为更小的域,{20 +,30 +,40 +,50 +},其中“ 20+”对应于区间 [20、29],“ 30+”至[30、39],并且以此类推。

Bayes’ Theorem
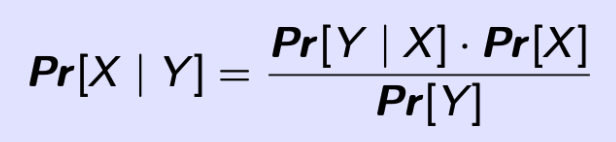
给定一个实例 x,我们预测它的标签是 -1 当且仅当
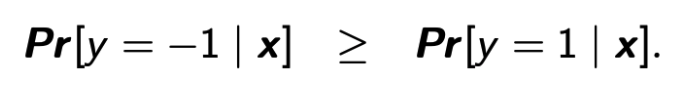
应用 Bayes’ Theorem,我们得到
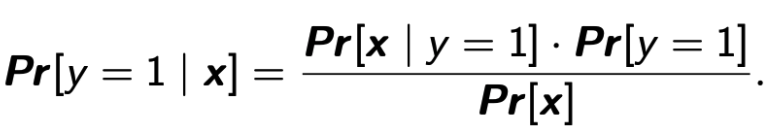
类似的
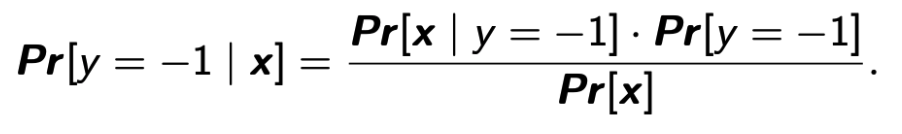
由于分母都一样,我们只需要比较分子哪个比较大,即
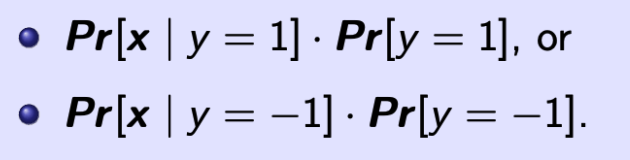
Bayesian Classification 通过训练集来估计上面两式的大小
Naive Bayes Classification

以标签 y = -1 的前提下,30+、udergrad、programmer的概率举例,假设 age 跟 education 是独立于 occupation 跟 class label 的,那么

Q & A
Q: Is number of attribute relevant to err_D(h)?
A: Yes and no. No 的原因是在 Generalization Theorem 里看不到 attribute,Yes 是因为它会间接影响 b
Q:We choose the number 0.001/(2^b) because if Pr(h fails) <= 0.001/(2^b) <= 0.001/|H| then Pr(none from H fails) >= 0.999
A:exactly
Q:Could you show how union bound conclude number δ/2b(这个问题本身是错的,但是也有可取之处)
A:
