CMSC 5724 Data Mining and Knowledge Discovery - Lecture 05
- Review
- VC-dimension
- VC-dimension of Extended Linear Classifies
- VC-Based Generalization Theorem
Review
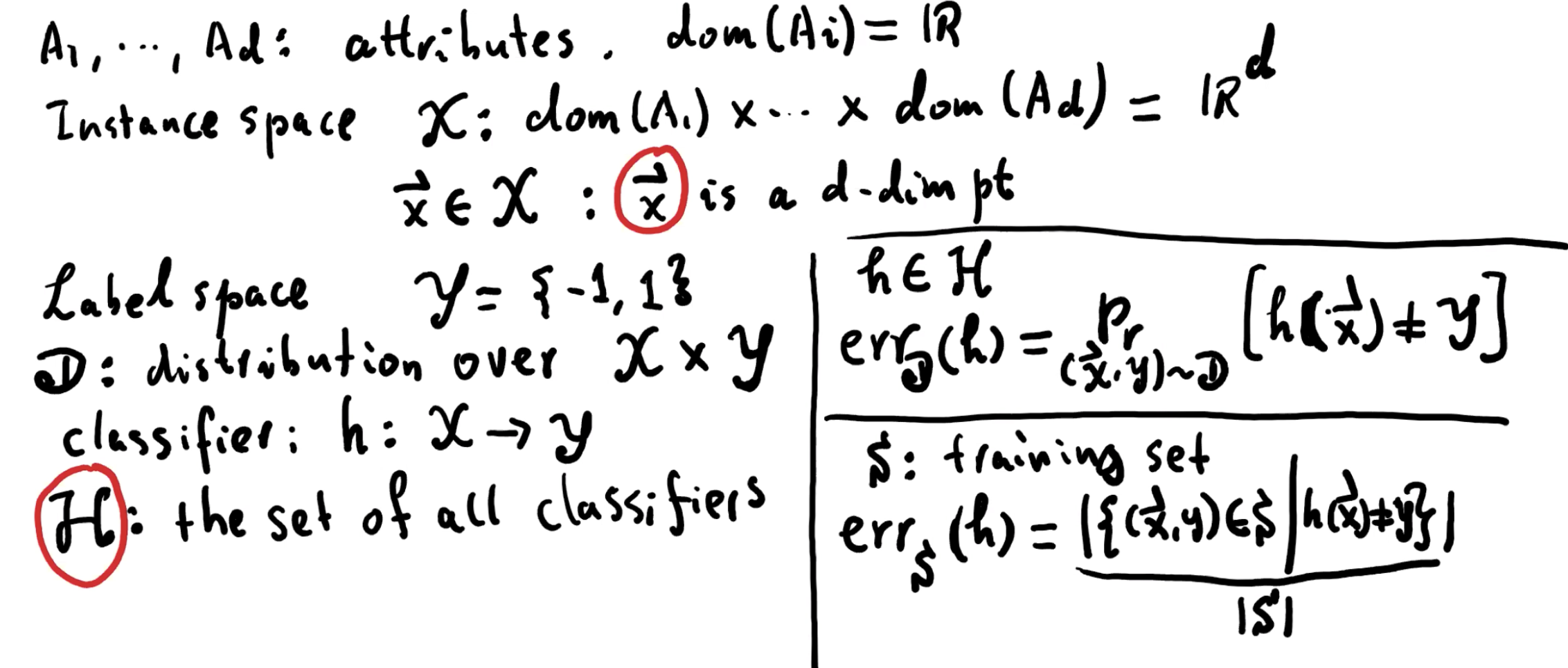

这里的 H 为 classifier 的总数,那么如果 H 趋于无限呢?那么就需要 Linear classification
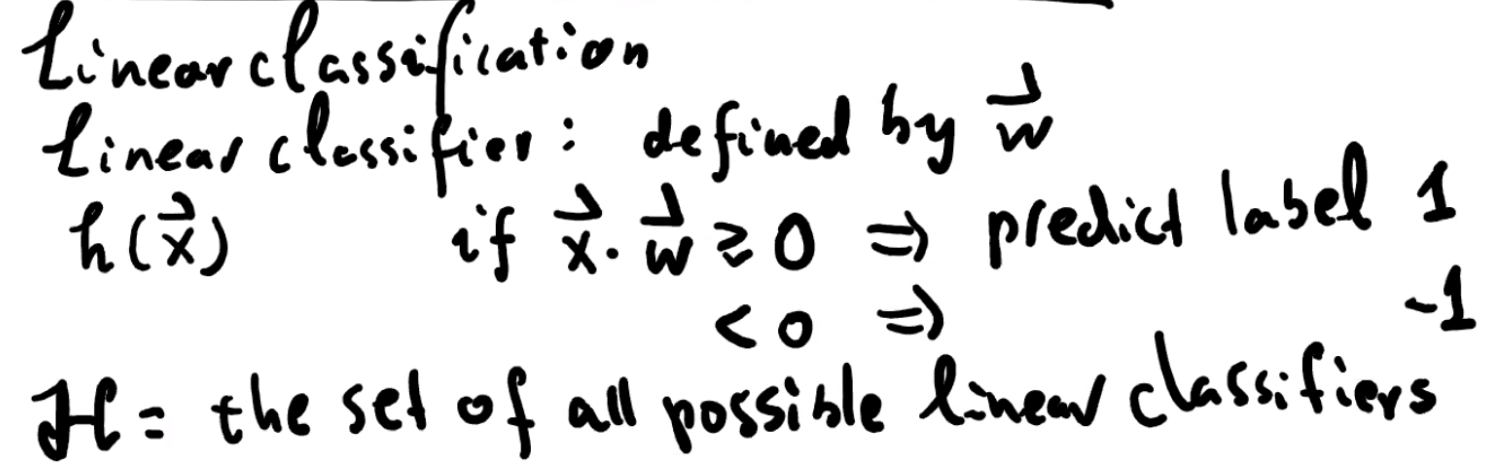
我们可以看出来第一节课讲的 Generalization Theorem 受限于需要知道 H 的大小,那么要如何摆脱,就需要 VC-dimension
VC-dimension
我们定义
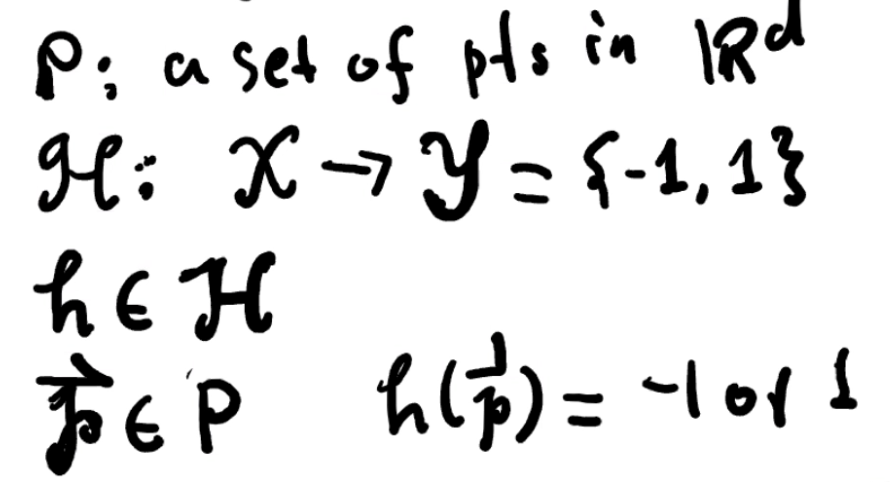
Example

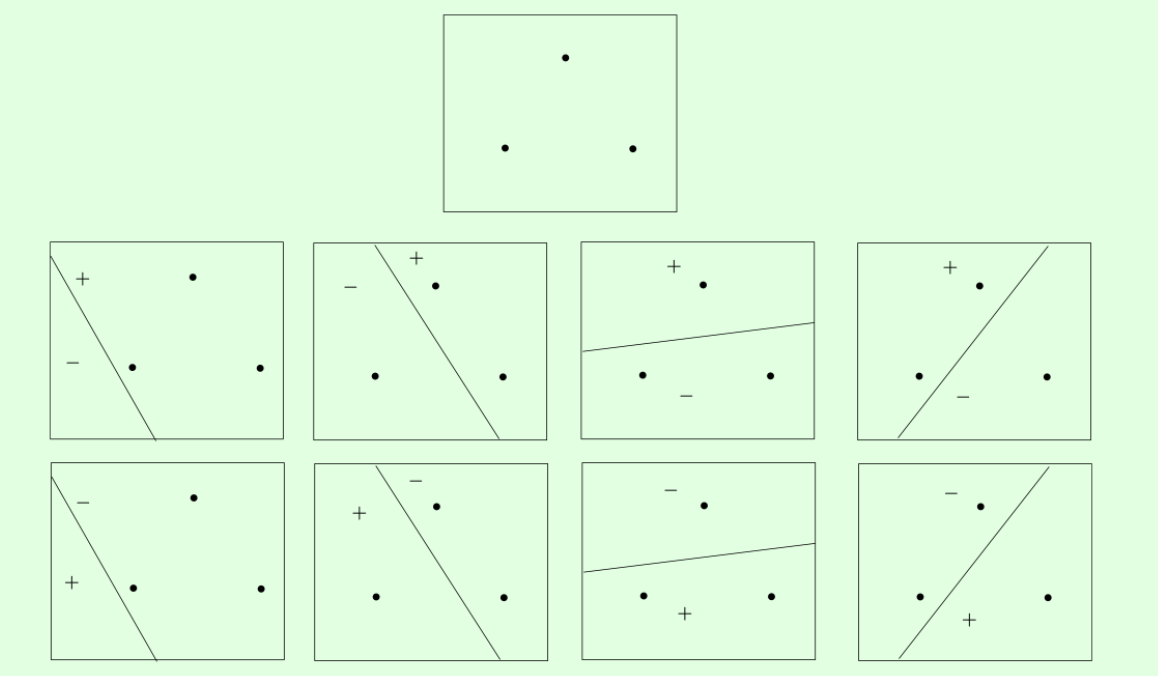
在二维空间内,对3个点的分割方式如下
Definition
这里就可以引出 VC-dimension 的定义
对于一个假设空间 H,如果存在 m 个数据样本能够被假设空间H中的函数按所有可能的 2^h 种形式分开 ,则称假设空间 H 能够把 m 个数据样本打散(shatter)。
假设空间 H 的 VC-dimension 就是能打散的最大数据样本数目 m。
若对任意数目的数据样本都有函数能将它们 shatter,则假设空间 H 的 VC-dimension 为无穷大。
在二维空间的4个点中,因为4个点的情况下不能做到对分,所以二维实平面上所有线性划分构成的假设空间 H 的 VC-dimension 为3。
课上对 VC-dimension 的定义为
令 P 为 X 的子集。H 在 P 上的 VC-dimension 是可以被 H shatter 的最大子集 P’⊆P 的大小。
如果 VC-dimension 是 λ,我们写作 VC-dim(P, H) = λ。
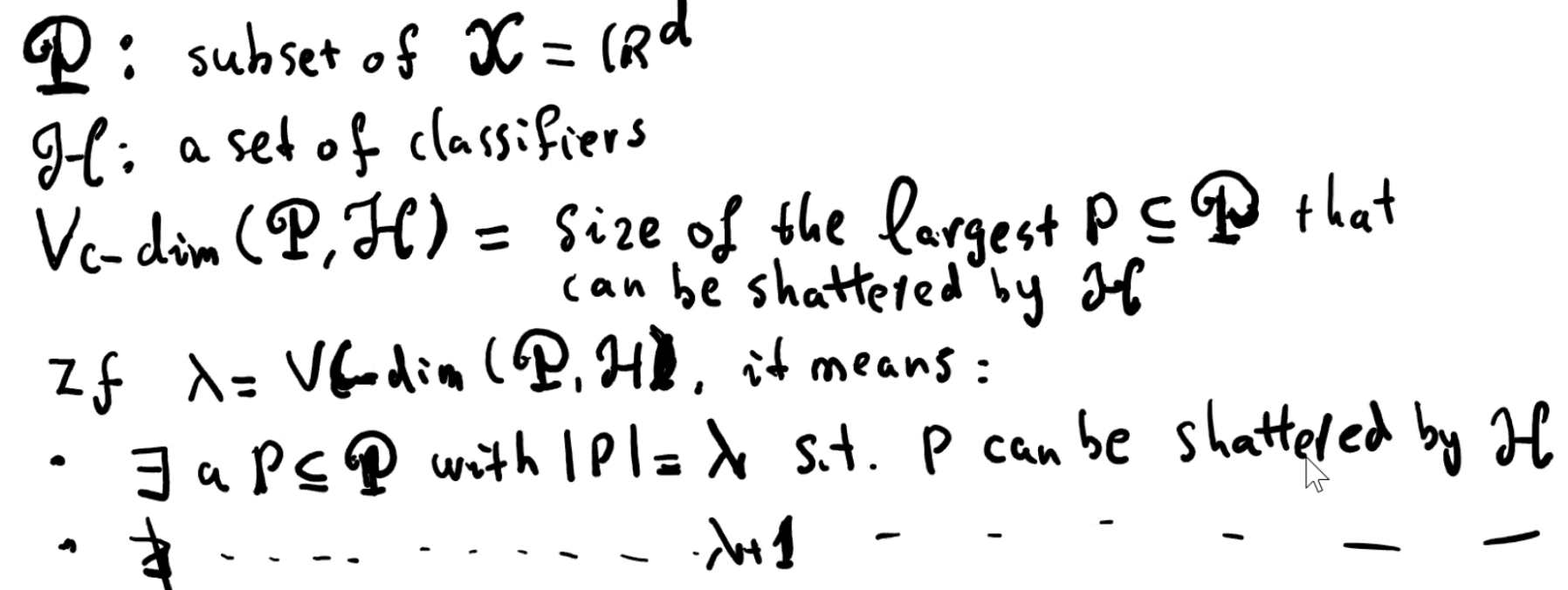
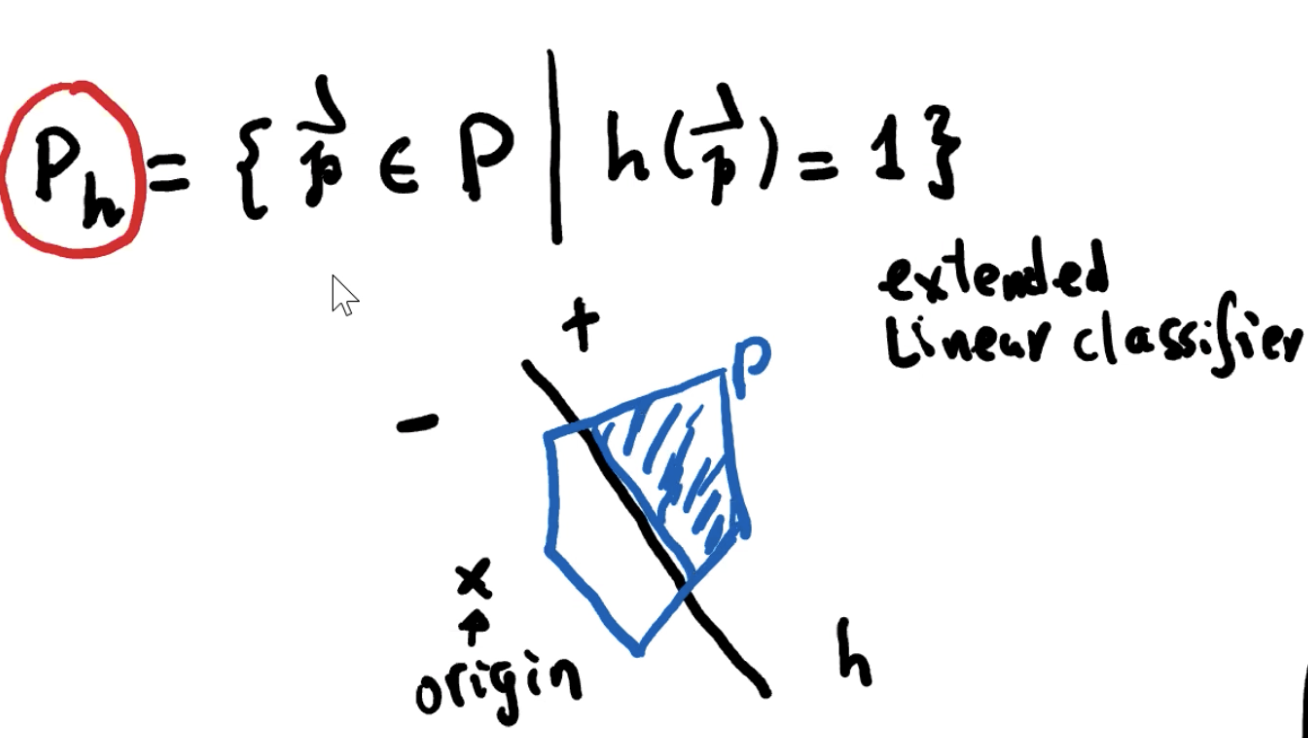
VC-dimension of Extended Linear Classifies
Theorem
令 H 为 extended linear classifies 的集合,则 VC-dim(R^d, H) = d + 1
Example
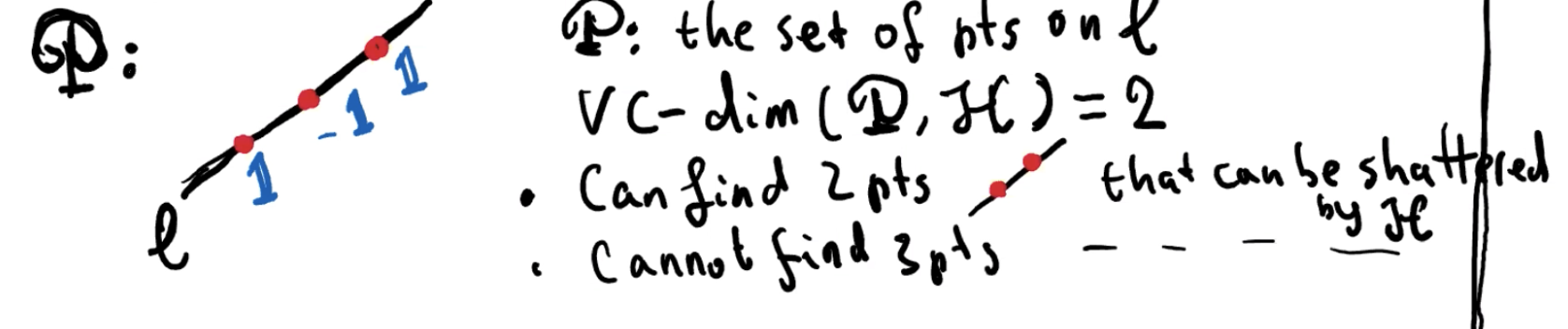
VC-Based Generalization Theorem
Support set of D
D 的 support set 是在 d 维实数集上,从 D 中取出的有正概率(概率密度函数pdf > 0)的集合。
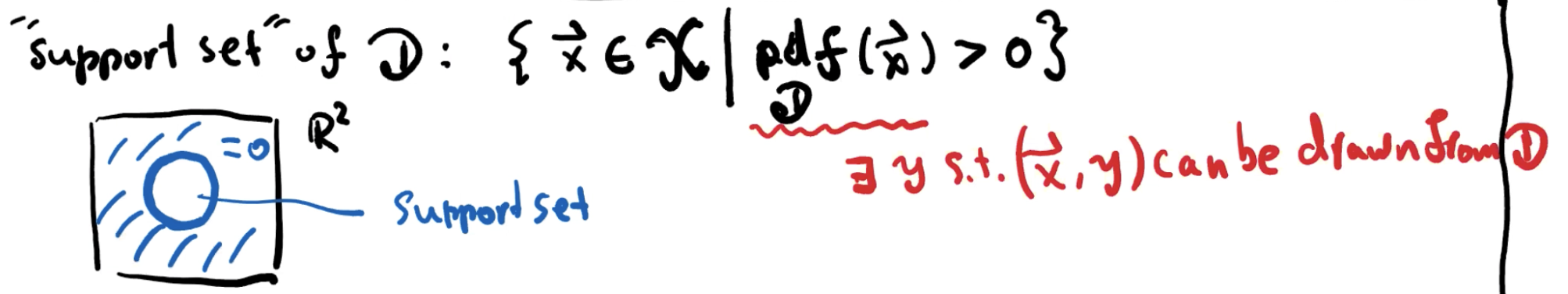
Theorem

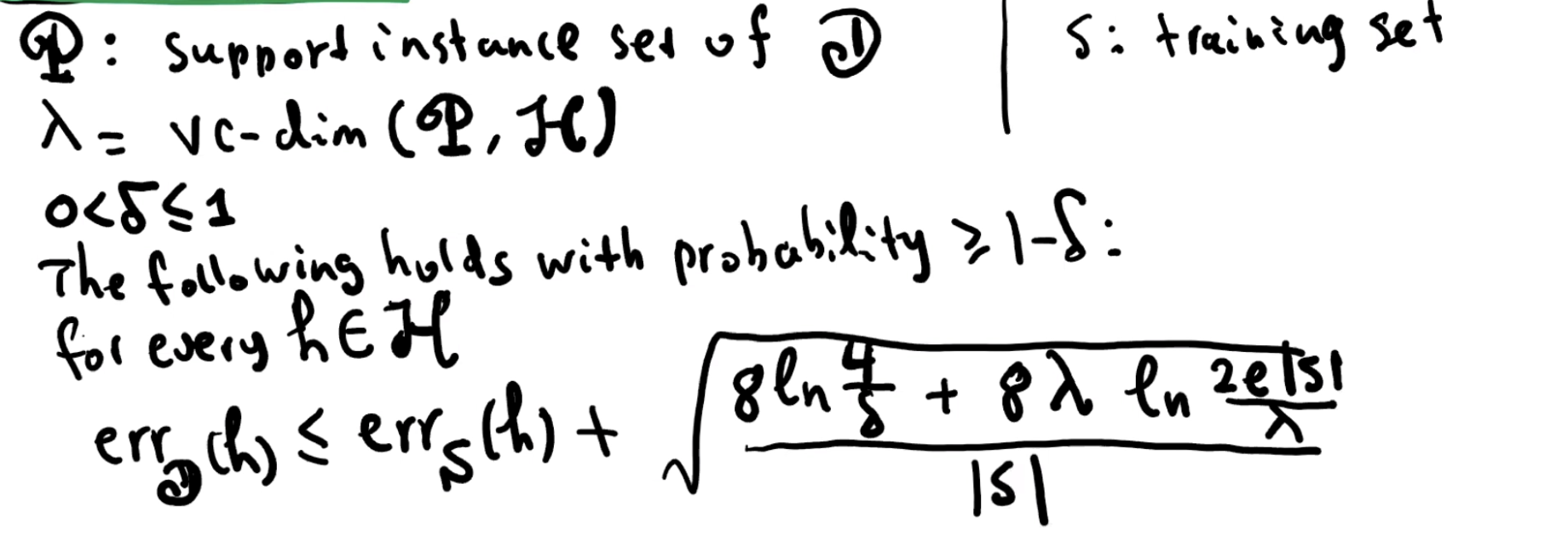
该理论对 H 的大小没有限制
如果一组 classifiers 是更强大的,即具有更大的 VC dimension,则学习起来会更加困难,因为需要更大的训练集。
对于 (extended) linear classifiers 的集合 H,训练集大小需要为 Ω(d) 以确保较小的 generalization error。当 d 大时,这就会成为问题。实际上,在某些情况下,我们甚至可能希望使用 d = 无限。
Recall Linear classifier
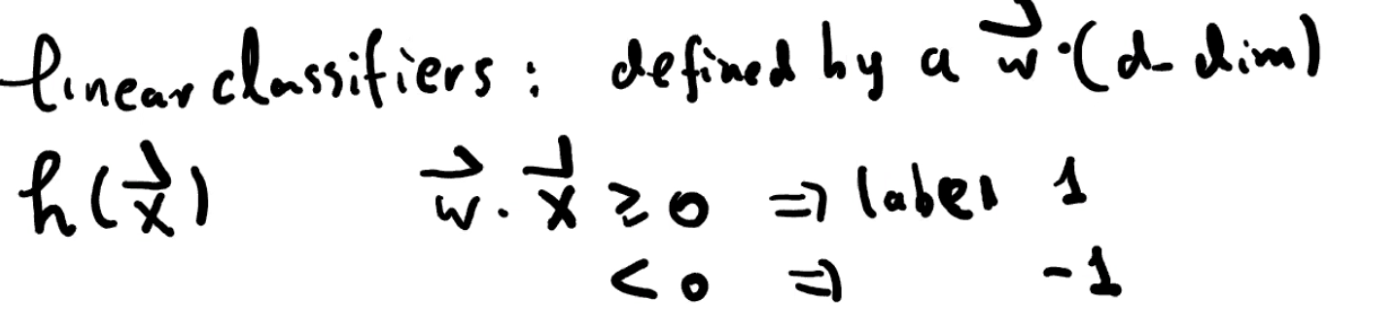
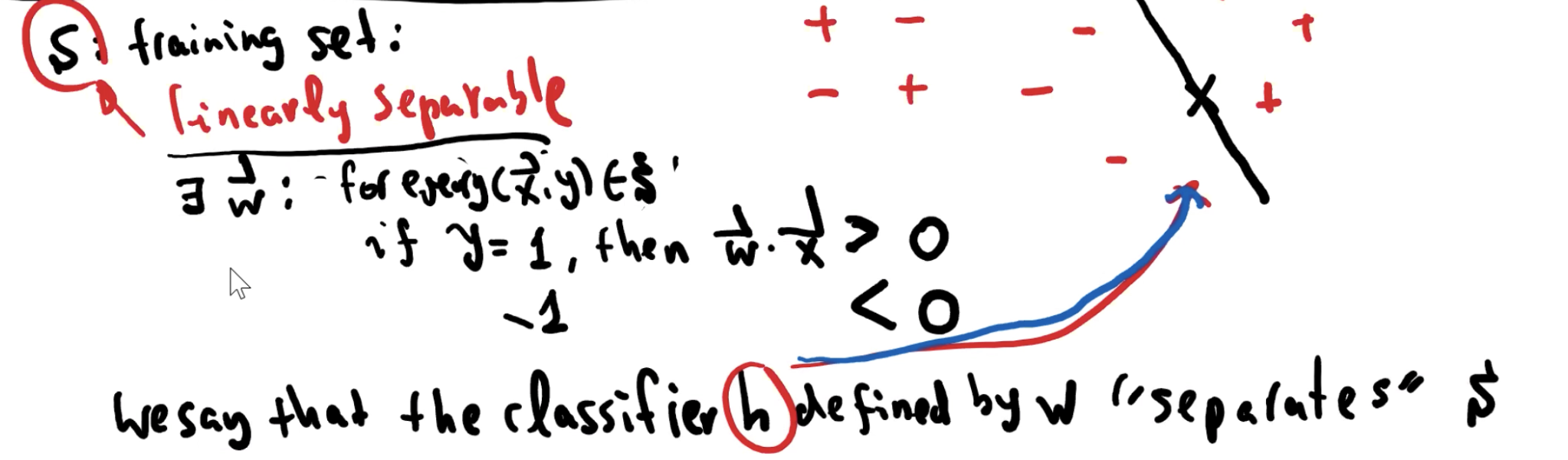
令 h 为由 d 维向量 w 定义的 linear classifier,我们说对于每个 p ∈ S,h 是 canonical,canonical 解释如下

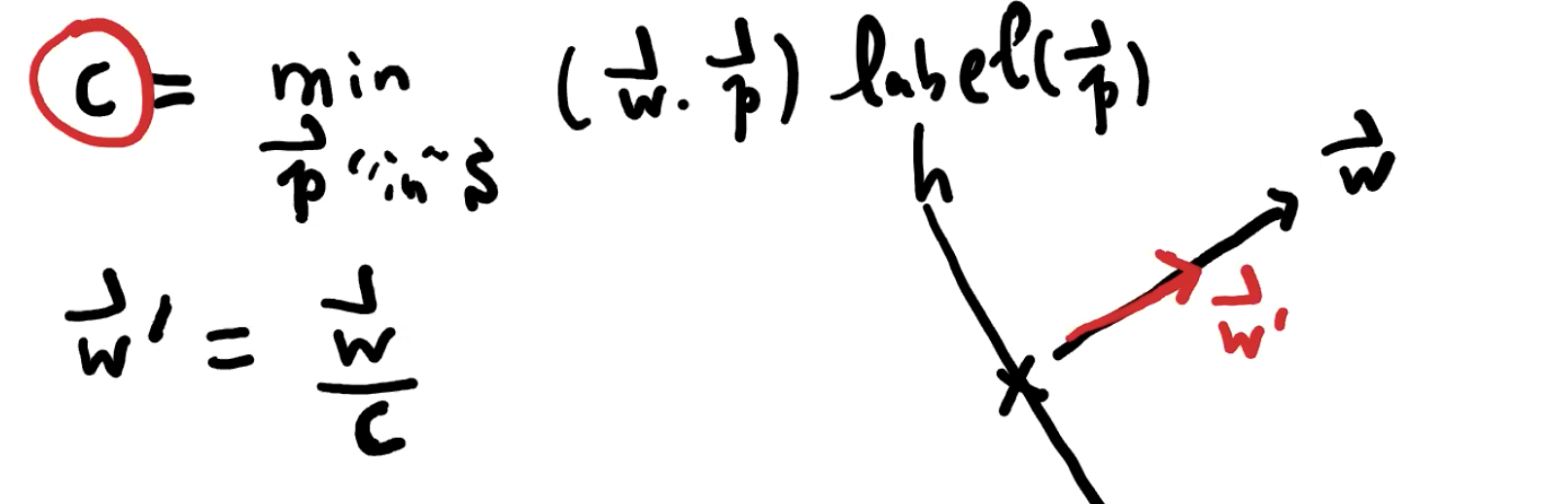
w‘ 就是 h 的 canonical 形式,canonical h 是一个由 w 描述的 classifier,它需要满足以下几点
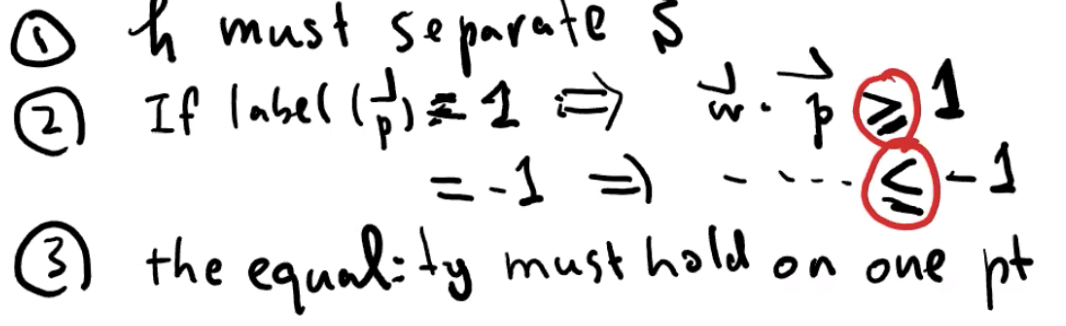
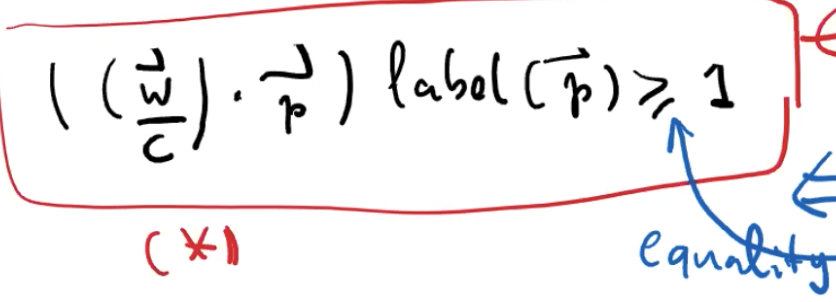
Margin-Based Generalization Theorem

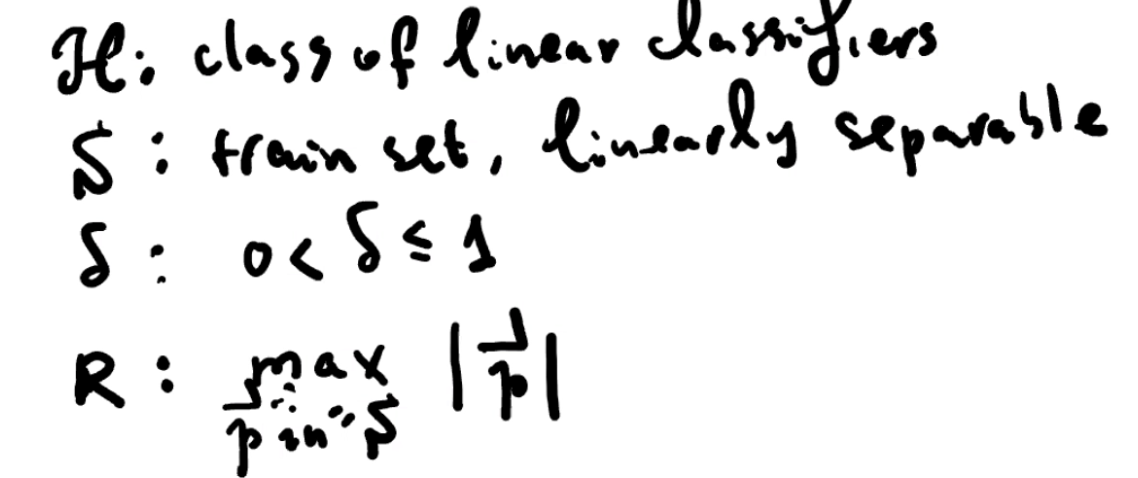
δ 满足 0 < δ ≤ 1,对于每个用 w 描述的 canonical h
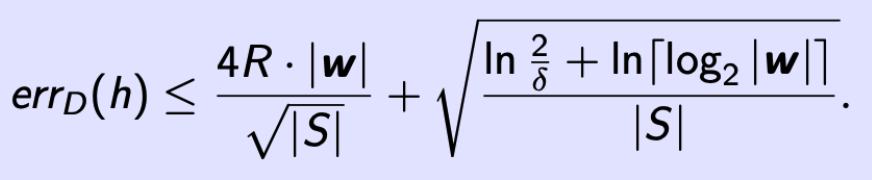
(这里没有 err_S(h),因为它总是为0)
这个 theorem 不依赖于维度 d
这个 theorem 为什么是 margin-based的?
由 w 定义的分割平面的 margin 等于 1/|w|(后面课程会得出)。
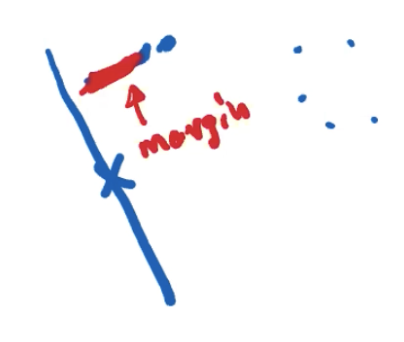
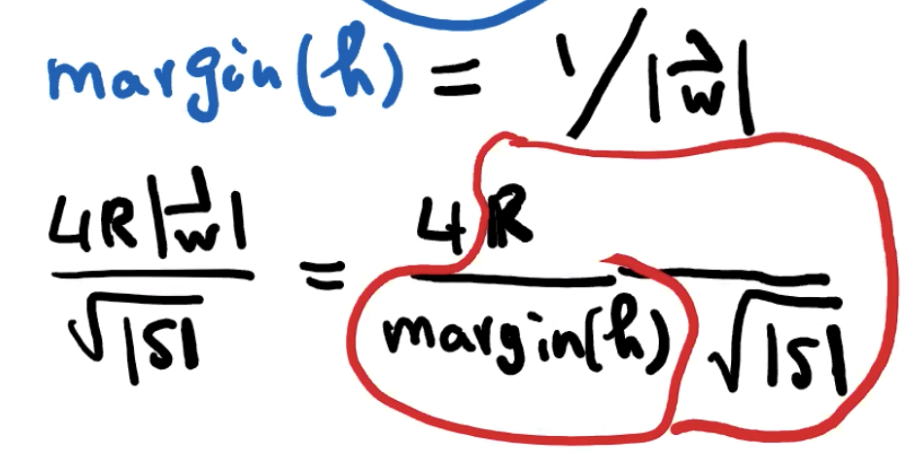
Question
怎么样算是被 shatter?能够被划分开?
为什么需要这两个 generalization theorem?
用基于VC-dimension 来限定 generalization error,所以任何分割平面都有很小的 generalization error
definition plane 不够好,所以需要第二个theorem。第二个 theorem 表示,如果能够增加 margin,可以更好地限制 generalization error。