CMSC 5728 Decision Analysis & Game Theory - Lecture 07
- Coalition
- Multi-armed Bandit (MAB)
Coalition
Superadditive Games
如果两个不相交的 coalitions 的联合至少值其成员之和,那么这个 coalitional game G = (N, v) 是 superadditive。N 是玩家的集合,v 是 payoff。
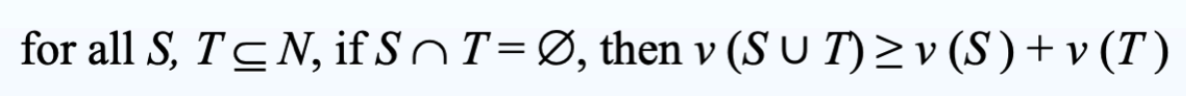
voting-game 是 superadditive
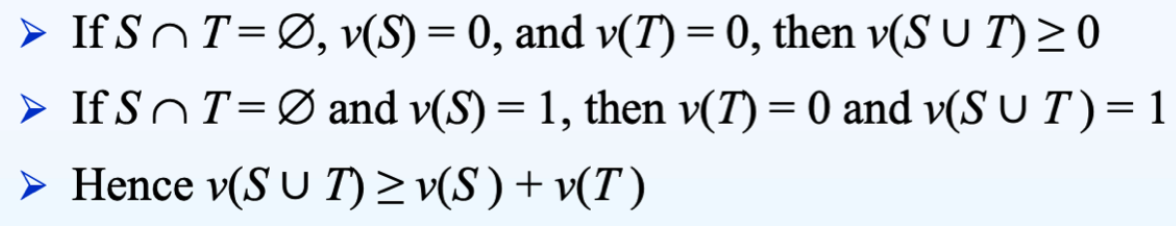
如果 G 是 superadditive,那么 grand coalition 总是会取得最高可能的 payoff
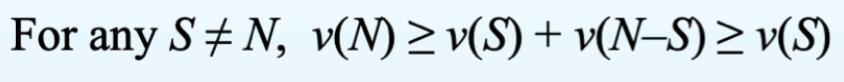
如果下面成立,那么 G = (V, v) 是 additive (或 inessential)
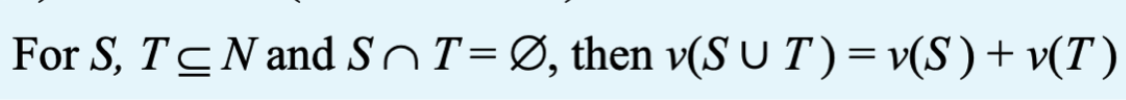
Constant-Sum Games
如果 grand coalition 的价值等于对 N 进行划分的任何两个 coalitions 的价值之和,则 G 为常数和
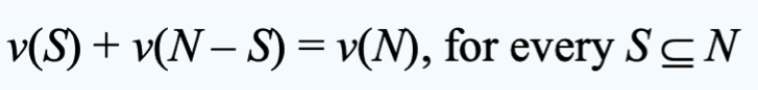
每个 additive game 都是 constant-sum game
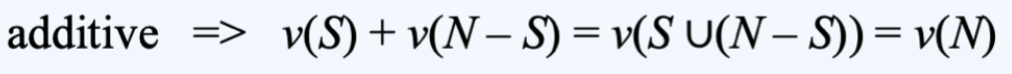
但是,并非每个 constant-sum game 都是 additive
Convex Games
对于所有 S, T ⊆ N,G 是 convex
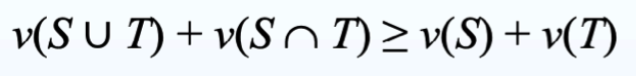
以上定义等同于 N 中所有 i 和所有 S ⊆ T ⊆ N - {i}
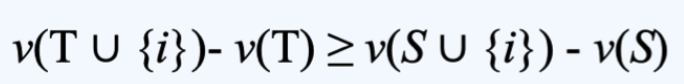
回想一下 superadditive game 的定义,我们可以得出每个 super-additive game 都是 convex game
Simple Coalitional Games
G = (N, v) 对于每个 coaliton S 是简单的
- v(S) = 1(win) 或 v(S) = 0 (lose)
通常添加一个要求,如果 S 获胜,则 S 的所有超集也获胜
- if v(S) = 1,所有 S ⊆ T,v(T) = 1
这并不意味着 super-additivity
- 一个 voting game G 需要 50% 投票来通过
- 两个 coalitions S 和 T,每个都有 50% 的 N
- v(S) = 1,v(T) = 1
- 但是 v(S ∪ T) ≠ 2
Proper-Simple Games
如果 G 同时是 simple 跟 constant-sum game,那么它是 proper simple game
- 如果 S 是 winning coalition,那么 N - S 是 losing coalition
- v(S) + v(N - S) = 1,所以如果 v(S) = 1,那么 v(N - S) = 0
- 如果 S 是 winning coalition,那么 N - S 是 losing coalition
games 分类的关系

Terminology
Feasible payoff set
= {所有 payoff 分布不超过 grand coalition}
= {(x1, …, xn) | x1 + … + xn} ≤ v(N)
Pre-imputation set
P = {feasible pay 是有效的,即分配 grand coalition 的全部价值}
= {(x1, …, xn) | x1 + … + xn} = v(N)
Imputation set
C = {P中的 payoff,其中每个 agent 至少获得一个通过单独行动(即,形成一个单人 coalition)将获得的 payoff}
= {(x1, …, xn) ∈ P: i ∈ N, xi ≥ v({i})}
Fairness & Symmetry
如果 agent i 和 j,总是对其他 agent 的每次coalition 贡献相同的金额,则他们是可互换的
- v(S ∪ {i}) = v(S ∪ {j})
在 payoff 的公平分配中,可互换的 agent 应该获得相同的 payment
- xi = xj
Dummy Players
- 如果 agent i 对任何 coalition 的贡献恰好是 i 可以单独实现的量,则 i 是 dummy player
- 对于 i ∉ S,v(S ∪ {i}) = v(S) + v({i})
- 在公平分配的 payoff 中,dummy player 应该获得与自己获得的金额相等的 payment
- 如果 i 是 dummy player 并且 (x1, …, xn) 是 payoff,那么 xi = v({i})
Additivity
- 令 G1 = (N, v1) 并且 G2 = (N, V2) 作为有相同 agents 的两个 coalitonal games
- 考虑 G = (N, v1 + v2)
- (v1 + v2)(S) = v1(S) + v2(S)
- 在公平分配 G 的 payoff 时,agent 应该得到他们在两个单独 games 中得到的总和
- 对于每个 player i,
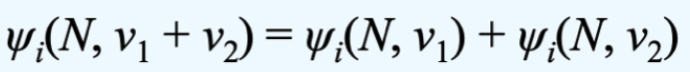
- 对于每个 player i,
Shapley Values
Theorem
给定一个 coalitional game (N, v),有一个唯一的 pre-imputation φ(N, v) 满足 symmetry、dummy play 和 additivity。对于每个 player i,i 的 φ(N, v) 份额是
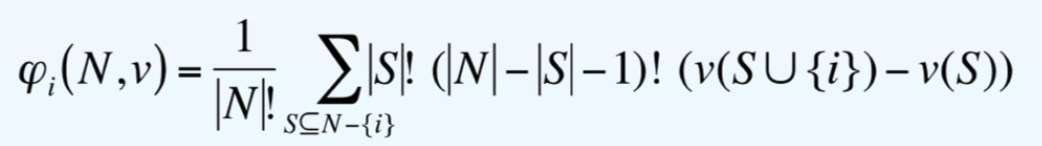
Example
voting game
- 政党 A、B、C、D 分别有 45、25、15、15 个代表
- 51 个投票以通过一百万账单
每个 coalition ≥ 51 个人都可以获得价值 1,其他 coalition 获得价值 0
两个 agents i 和 j 可以互换的含义
- v(S ∪ {i}) = v(S ∪ {j})
B 与 C 可互换
- 对于 ∅ 来说是 0,因为 B 或 C 加上 ∅ 都不够票数
- 对 {A} 来说是1,因为加上 A 后的票数大于51
- 对 {A, D} 来说是 0,因为 {A, D} 的票数已经大于51
同样地,B、D 是可互换的,C 与 D 也是
所以根据 fairness,B、C、D 应该有同样的 amount
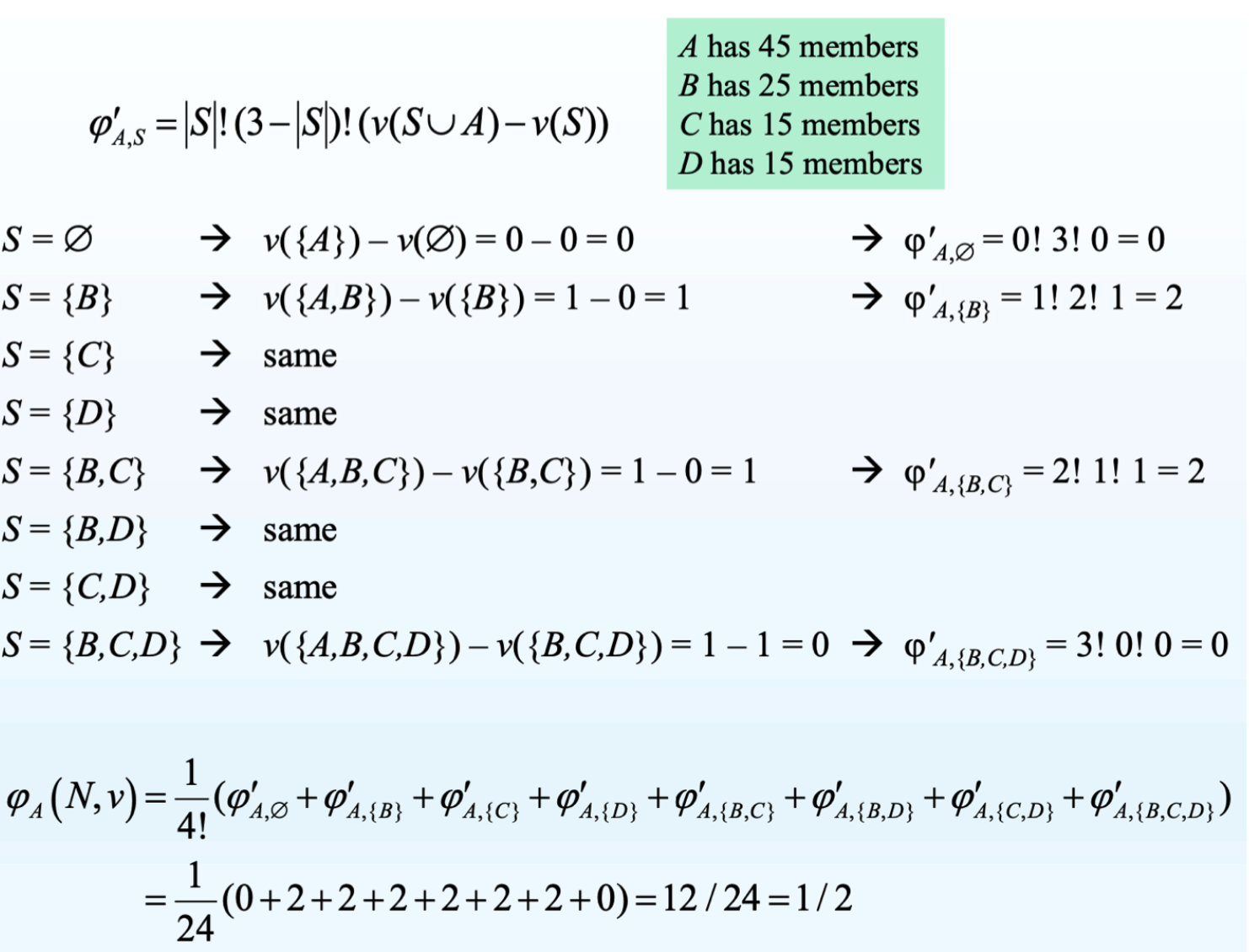
- 类似地,φB = φC = φD = 1/6
- 如果 A 获得 1/2,那么剩下 1/2 会分给 B、C 、D
- 它们是可互换的,所以会平分:1/6
- 所以金钱的分配如下
- A 获得 1/2 * 100M = 50M
- B、C、D 每个获得 1/6 * 100m
Multi-armed Bandit (MAB)
- MAB 是进行在线决策的框架属性
- 在线:学习者没有完整的数据集,但是在学习者做出决策时(通常是学习者要优化一些目标功能)数据会正在进来
- 顺序决策:学习者做出决策,然后观察系统,然后做出下一个决策
- 通常来说,学习者需要在随机环境下做出顺序决策
- 总体框架
- 时隙系统:t = 1, 2, …, T
- 每个时间点学习者有 N ∈ N+ 个选择
- 在每个时间点 t ∈ [T]
- 学习者在 N 中选择一个选择(在其他情况下,学习者可以在一个时间点做出 K ≤ N 个选择)
- 在做决策的时候,学习者可以依赖过往经验或观察结果
- 在学习者做出决策后,学习者可以观察到 reward (可能是随机的)
- 目标:做出正确决定以最大化总 reward 以及其他可能的目标,如满足某些约束
Sequential decision
common features
- 一个人只能使用过去的观察(或反馈)和过去的动作在当前时间步长做出决定
- 过去的观察/反馈必须与将来的奖励有一定关系(存在相关性)。 如果没有相关性,就很难学习任何东西。
- 关键:我们应该从过去中学习,以便改善未来(例如,优化我们的累积奖励)
- 我们可以利用我们的统计知识来估计决策/选择的良好程度。
- 我们必须考虑 “exploration” 和 “exploitation”
Different variation
- 我们可以使用随机变量来表示它,例如 IID。 这是 MAB 中的主要方法
- 我们可以用随机过程来表示它,这叫 Markov chain。 这是 RL 中的主要方法
- 我们可以使用 adversary 来建模(一种任意反馈序列,但在某些特定方式上受限)
Distinctions
- 完整信息模型
- 奖励你的决定,但对所有可能选择(例如,购买股票)的即时表现提供反馈
- 在完整信息模型中,我们可以回答 what-if
- 反馈在决定之前或者之后
- 受限反馈模型
- 反馈只在你的决定的表现情况
Multi-armed Bandit model
- N 个 arms 或选择
- 拉下 arm 的时候产生一个 reward
- 在每次时间点 t = 1, 2,…, T,拉一个 arm It ∈ {1,2,…,N}
- 我们观察到 reward rt ∈ R
- 我们的目标是最大化 Σrt
- 这是一个受限反馈模型,因为因为你只能观察到您拉出的手臂的奖励,而无法观察其他手臂的奖励
Exploitation & Exploration
- 自然的选择是迄今为止最好的选择,例如,只选择那些已经选择的 arm,然后选择给予学习者最高奖励的arm
- 这称为 “exploitation”。
- 尝试使用一些未开发的 arm 或很少拉的 arm,因为它们可能会提供更高的奖励
- 这称为 “exploration”
Key properties
Key
适应过去(学习)来保证不会浪费在不好的 arms 上
Idea1: Estimation
Estimation:可以估计获胜的经验平均值
令 X 表示一个 arm 的结果 losing(0) 或 winning(1) 的伯努利随机变量。令 Xi,i ∈ {1,2,…} 作为第 i 个观察量。令 μ = E[X] 作为 X 的平均值。经验平均值是
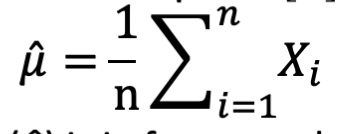
经验平均值
 是一个随机变量,所以它有一个概率分布。
是一个随机变量,所以它有一个概率分布。它还是一个 μ 的 unbiased estimator(无偏估计量)
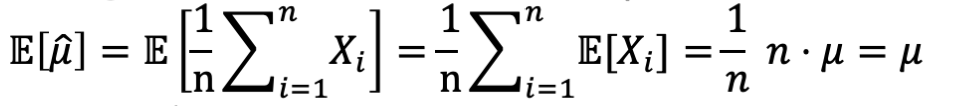
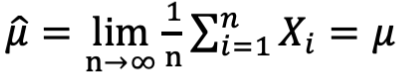
总之,我们可以用经验平均值来估计 arm 的优劣。
Idea2
How many estimation we need so to have an accurate 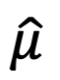 ?
?
- 尽管我们知道当观察数量很大时
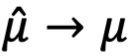 ,但是我们希望基于对不同 arms 的有限观察来做出良好的 arm 选择
,但是我们希望基于对不同 arms 的有限观察来做出良好的 arm 选择 - 由于 是一个随机变量,因此如果我们可以用很高的概率断言 在某个下限和上限之间,这将有助于我们选择 arm
- 例如,我们有 3 个 arms,我们知道一个 ∈ (0.2, 0.4),一个 ∈ (0.3, 0.6)并且 另一个 ∈ (0.5, 0.7),那我们不会选择第一个
- 再例如,我们知道我们知道一个 ∈ (0.2, 0.4),一个 ∈ (0.3, 0.6)并且 另一个 ∈ (0.65, 0.9),那我们不会选择第三个
- 为了使我们的经验估计值在一定区间内,我们需要研究 concentration bounds(集中度边界)的概念,尤其是要了解 Hoeffding 不等式。