CMSC 5728 Decision Analysis & Game Theory - Lecture 08
- MAB: Stochastic (IID)
- Adversarial MAB
- Stochastic but not IID
- MAB Problem definion
- Stochastic Reward model
- Regret
- Concentration Bounds
- Markov’s Inequality
MAB: Stochastic (IID)
对每个 arm i ∈ {1, …, N},reward 从固定但未知的分布 vi (如正态分布或均匀分布)中独立且相同地生成,平均值为 μi

我们定义历史为 Ht-1 来包括时间 t 之前做出的所有决定和观察
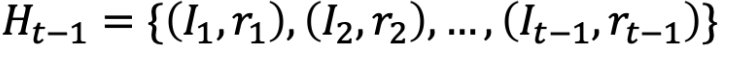
给定历史 Ht-1,在时间 t 选择 arm It = i
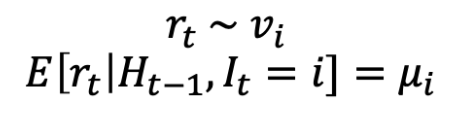
此时,你获得的 reward rt 是跟随 random variable vi 的,这个 random variable 的平均值是 μi。
我们在上节课讲过,如果我们知道所有的 μ,我们只要每次选择最大的 μ,就是最优选择,但现在我们不知道,那么要怎么去选择呢?
How to evaluate
Regret:算法的总 reward 与 “benchmark” 算法之间的差距
benchmark algorithm:借助分布知识来构建最佳策略(即使它们可能无法实现,不在我们的 μ 中)
总是采取我们所知道的 μi 中最高那个
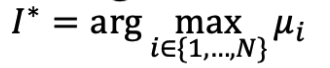
在时间 T (总时间)积累的平均 reward,即在 T 中一直选择最优的 μi 的和
在 T 中的 regret
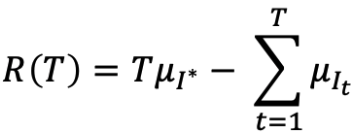
即使是确定性的选臂策略,其数量也是随机的(?)
目标:限定预期的 regret 或高概率的界限
Adversarial MAB
我们部队 reward 产生过程做任何假设:除了数量上的界限(?)
任意未知序列:
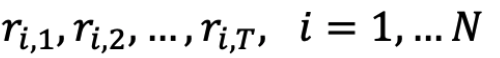
在时间 t 选择 arm It,我们算法的 reward 是
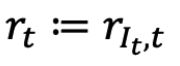
什么是 adversary
仅仅意味着奖励生成过程是对抗性的,并为你的算法提供了最坏的奖励序列
一般情况下,这是个绝望的问题
- 未来与过去无关
- 不管你在时间 t 做出了什么决定,adversary 会做出最坏的决定
更为谦虚的目标
事后我们能否与 SINGLE BEST ARM 竞争?
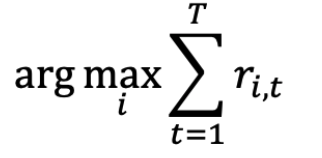
在时间 T 的 regret
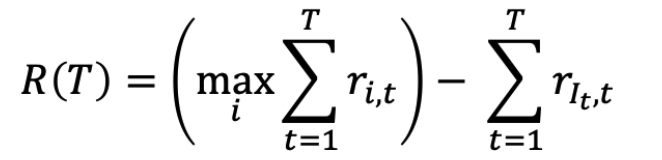
Stochastic but not IID
Markovian inputs:
- 不同 arm 的奖励是独立的
- arm 的 reward 分布仅取决于过去的可观察 arm 状态,并且 arm 的状态可以更改,例如 Markov chain
- 状态转换的不确定性和给予的 reward 状态
- 每次拉 arm 时,都会观察到其 reward 和状态转换
MAB Problem definition
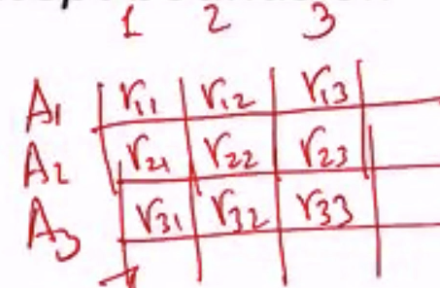
- N arms
- 在每个时间点 t = 1, 2, 3, …,拉一个 N 中的 arm
- 令 It ∈ {1, 2, …, N} 作为在第 t 个时间点拉的 arm
- 在拉 arm 之后,我们可以观察(或收到)一个 reward rt ∈ [0, 1](Bernouli R.V.)
- 对于一个固定的 T,我们的目标是最大化
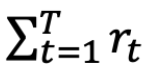
Stochastic Reward model
随即假设与 IID 模型
来自 arm i 的 reward 遵循均值 μi 的概率分布 vi
在我们之前的 formulation 中,vi 遵循 Bernoulli distribution
当拉一个 arm 时,reward 会从分布 vi 中产生(正态分布或均匀分布或exp分布)
令
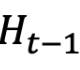 表示直到时间点 t - 1 的历史,我们可以写作
表示直到时间点 t - 1 的历史,我们可以写作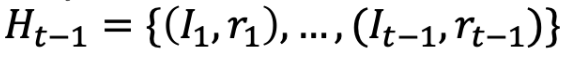
那么我们在 reward 的假设可以写作

这也暗示:
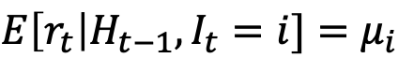
或者,给定截止时间 t - 1 并选择 arm It 的历史记录,将独立于所选 arm 的分布来获取奖励
Performance Evaluation: Regret
任何 arm 选择算法都会与 oracle 进行比较
oracle 了解概率分布 vi i ∈ {1, …, N} 并且在所有时间点选择最好的 arm。或者
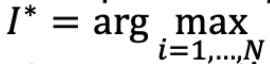 和
和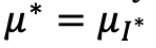 分别是最佳 arm 的索引和最佳 arm 的平均 reward
分别是最佳 arm 的索引和最佳 arm 的平均 reward在时间 T 的 regret 是
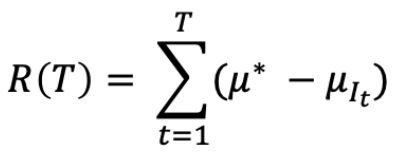
我们的目标是最小化 R(T)。注意 R(T) 是一个随机变量,因为 It 是随机的。(E[R(T)] 是 average total mistakes)
定义期望的 regret
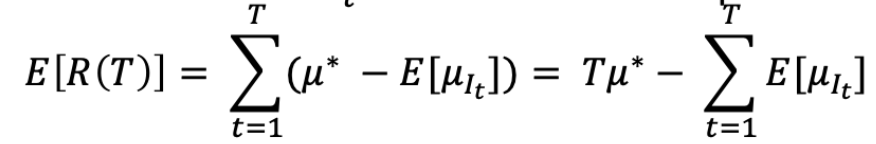
通常,我们想要 regret E[R(T)] 是 sub-linear。
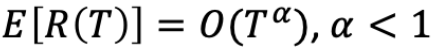
Concentration Bounds
不失一般性,考虑我们要估计 arm 1 的获胜概率
我们知道它的 reward 是 Bernoulli 随机变量 X,有 0 或 1,并且概率分别是 (1 - μ) 和 μ
所以平均 reward 是 0 × (1 - μ) + 1 × μ = μ
令 X1, X2, …, Xn 为一系列独立且分布均匀的随机变量(它们是 X 的 IID)。换句话说,Xi 是 arm 1 输出的第 i 个样本(或观察)
此外,令均值 μ = E[Xi] < 无限,并且对于所有 i ∈ {1,2, …, n},方差是
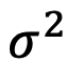 = E[Xi] < 无限
= E[Xi] < 无限为了估计 μ,使用 empirical mean
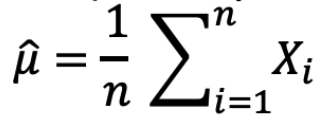
这是一个随机变量,因为 Xi 有随机变量的值
同时还是 μ 的 unbiased estimator
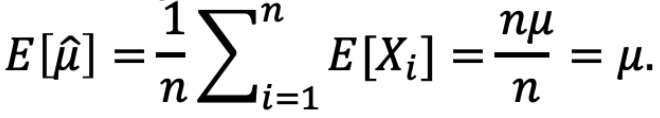
因为 Xi 是 IID,变量
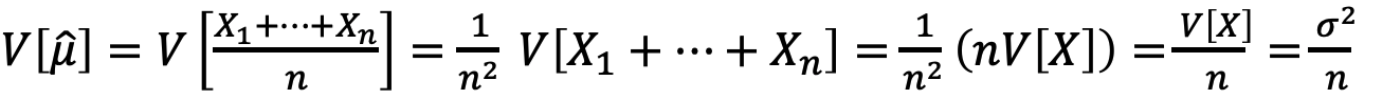
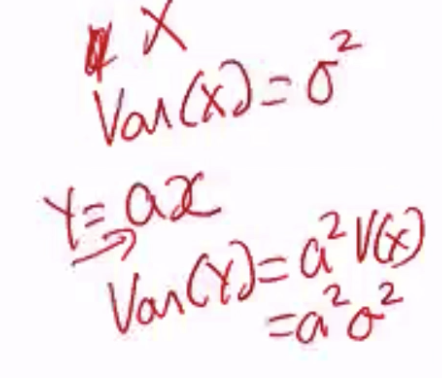
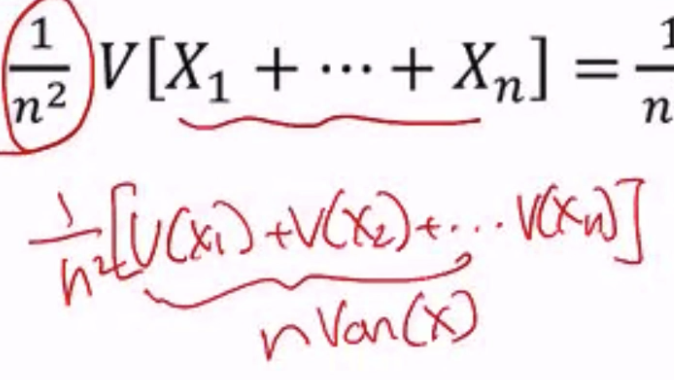
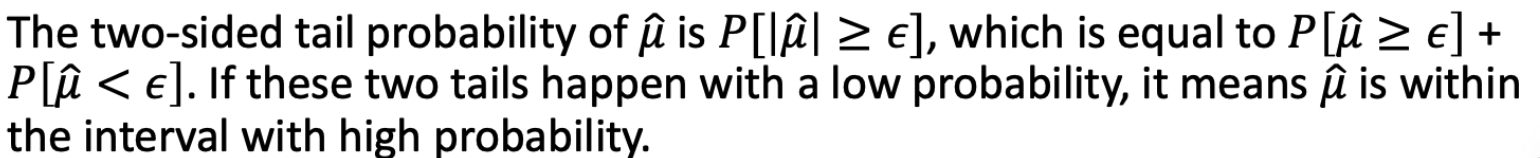
Markov’s Inequality
Lemma
对于任意随机变量 X 并且 ε > 0,我们有
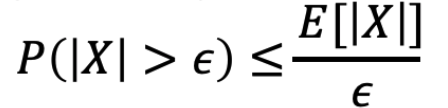
Proof
令 Y = |X|,所以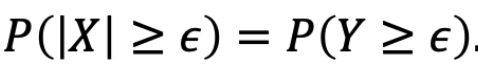 注意 Y 是一个非负随机变量
注意 Y 是一个非负随机变量
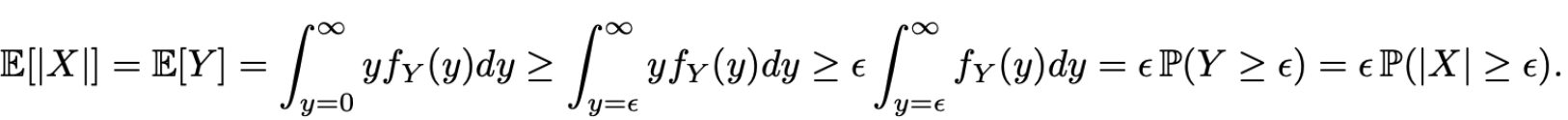
所以我们有
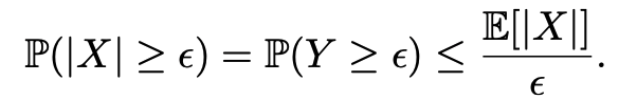
另一种方法
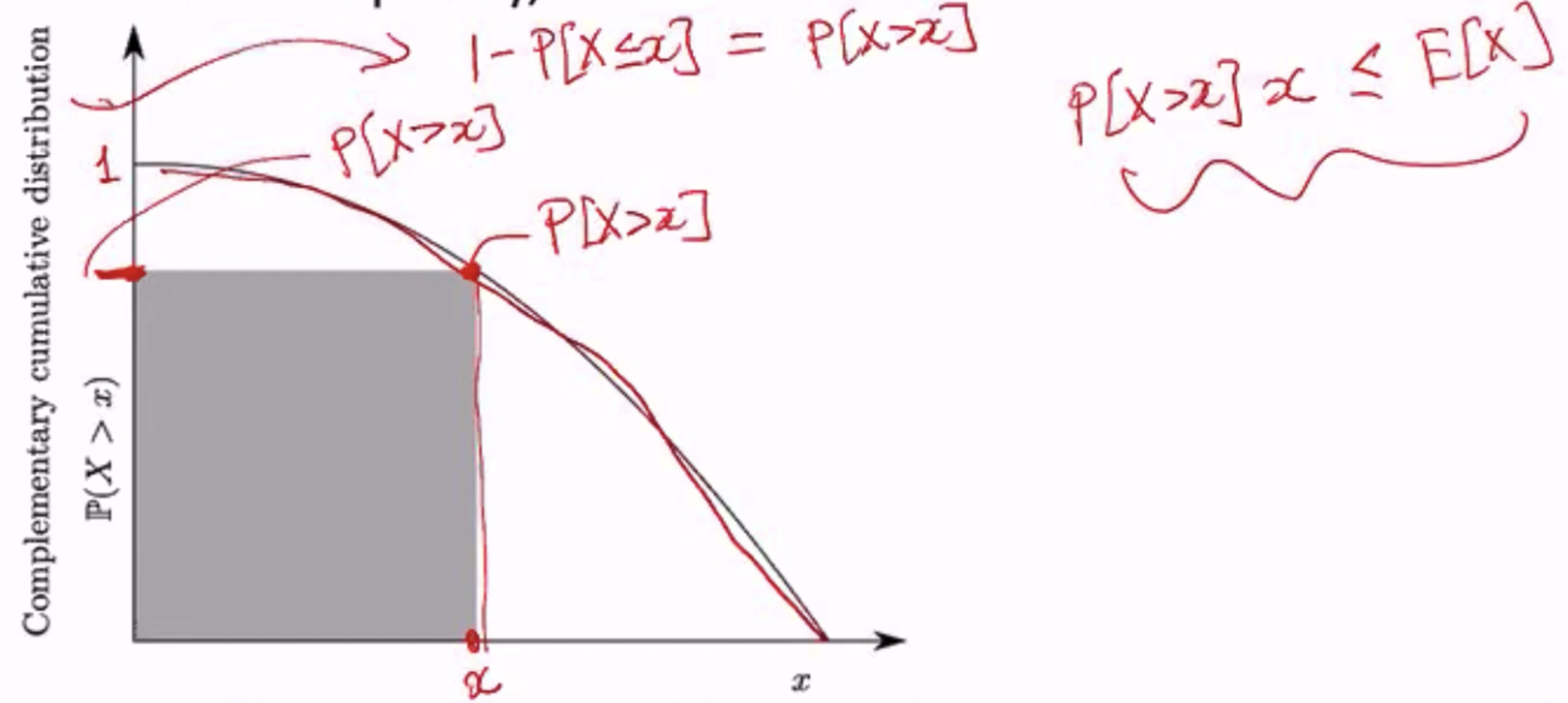
考虑一个非负离散随机变量 X,E[X] = 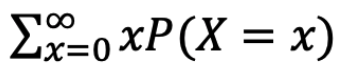
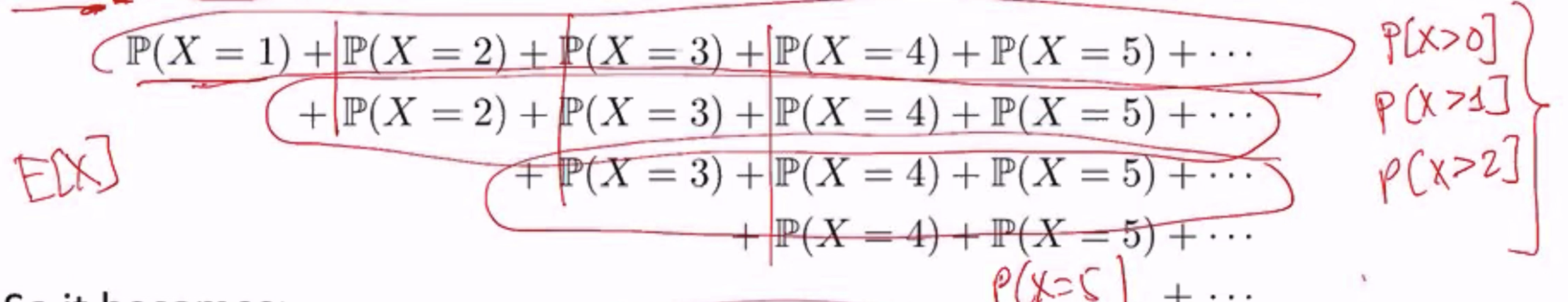
所以会变成
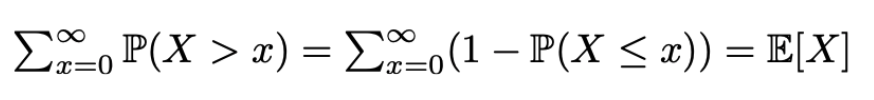
用图来观察